One of our weapons in the fight against spam, malware, and other abuse on Facebook is a system called Sigma. Its job is to proactively identify malicious actions on Facebook, such as spam, phishing attacks, posting links to malware, etc. Bad content detected by Sigma is removed automatically so that it doesn’t show up in your News Feed.
We recently completed a two-year-long major redesign of Sigma, which involved replacing the in-house FXL language previously used to program Sigma with Haskell. The Haskell-powered Sigma now runs in production, serving more than one million requests per second.
Haskell isn’t a common choice for large production systems like Sigma, and in this post, we’ll explain some of the thinking that led to that decision. We also wanted to share the experiences and lessons we learned along the way. We made several improvements to GHC (the Haskell compiler) and fed them back upstream, and we were able to achieve better performance from Haskell compared with the previous implementation.
How does Sigma work?
Sigma is a rule engine, which means it runs a set of rules, called policies. Every interaction on Facebook — from posting a status update to clicking “like” — results in Sigma evaluating a set of policies specific to that type of interaction. These policies make it possible for us to identify and block malicious interactions before they affect people on Facebook.
Policies are continuously deployed. At all times, the source code in the repository is the code running in Sigma, allowing us to move quickly to deploy policies in response to new abuses. This also means that safety in the language we write policies in is important. We don’t allow code to be checked into the repository unless it is type-correct.
Louis Brandy of Facebook’s Site Integrity team discusses scalable spam fighting and the anti-abuse structure at Facebook and Instagram in a 2014 @Scale talk.
Why Haskell?
The original language we designed for writing policies, FXL, was not ideal for expressing the growing scale and complexity of Facebook policies. It lacked certain abstraction facilities, such as user-defined data types and modules, and its implementation, based on an interpreter, was slower than we wanted. We wanted the performance and expressivity of a fully fledged programming language. Thus, we decided to migrate to an existing language rather than try to improve FXL.
The following features were at the top of our list when we were choosing a replacement:
1. Purely functional and strongly typed. This ensures that policies can’t inadvertently interact with each other, they can’t crash Sigma, and they are easy to test in isolation. Strong types help eliminate many bugs before putting policies into production.
2. Automatically batch and overlap data fetches. Policies typically fetch data from other systems at Facebook, so we want to employ concurrency wherever possible for efficiency. We want concurrency to be implicit, so that engineers writing policies can concentrate on fighting spam and not worry about concurrency. Implicit concurrency also prevents the code from being cluttered with efficiency-related details that would obscure the functionality, and make the code harder to understand and modify.
3. Push code changes to production in minutes. This enables us to deploy new or updated policies quickly.
4. Performance. FXL’s slower performance meant that we were writing anything performance-critical in C++ and putting it in Sigma itself. This had a number of drawbacks, particularly the time required to roll out changes.
5. Support for interactive development. Developers working on policies want to be able to experiment and test their code interactively, and to see the results immediately.
Haskell measures up quite well: It is a purely functional and strongly typed language, and it has a mature optimizing compiler and an interactive environment (GHCi). It also has all the abstraction facilities we would need, it has a rich set of libraries available, and it’s backed by an active developer community.
That left us with two features from our list to address: (1) automatic batching and concurrency, and (2) hot-swapping of compiled code.
Automatic batching and concurrency: The Haxl framework
All the existing concurrency abstractions in Haskell are explicit, meaning that the user needs to say which things should happen concurrently. For data-fetching, which can be considered a purely functional operation, we wanted a programming model in which the system just exploits whatever concurrency is available, without the programmer having to use explicit concurrency constructs. We developed the Haxl framework to address this issue: Haxl enables multiple data-fetching operations to be automatically batched and executed concurrently.
We discussed Haxl in an earlier blog post, and we published a paper on Haxl at the ICFP 2014 conference. Haxl is open source and available on GitHub.
In addition to the Haxl framework, we needed help from the Haskell compiler in the form of the Applicative do-notation. This allows programmers to write sequences of statements that the compiler automatically rearranges to exploit concurrency. We also designed and implemented Applicative do-notation in GHC.
Hot-swapping of compiled code
Every time someone checks new code into the repository of policies, we want to have that code running on every machine in the Sigma fleet as quickly as possible. Haskell is a compiled language, so that involves compiling the code and distributing the new compiled code to all the machines running Sigma.
We want to update the compiled rules in a running Sigma process on the fly, while it is serving requests. Changing the code of a running program is a tricky problem in general, and it has been the subject of a great deal of research in the academic community. In our case, fortunately, the problem is simpler: Requests to Sigma are short-lived, so we don’t need to switch a running request to new code. We can serve new requests on the new code and let the existing requests finish before we discard the old code. We’re careful to ensure that we don’t change any code associated with persistent state in Sigma.
Loading and unloading code currently uses GHC’s built-in runtime linker, although in principle, we could use the system dynamic linker. To unload the old version of the code, the garbage collector gets involved. The garbage collector detects when old code is no longer being used by a running request, so we know when it is safe to unload it from the running process.
How Haskell fits in
Haskell is sandwiched between two layers of C++ in Sigma. At the top, we use the C++ thrift server. In principle, Haskell can act as a thrift server, but the C++ thrift server is more mature and performant. It also supports more features. Furthermore, it can work seamlessly with the Haskell layers below because we can call into Haskell from C++. For these reasons, it made sense to use C++ for the server layer.
At the lowest layer, we have existing C++ client code for talking to other internal services. Rather than rewrite this code in Haskell, which would duplicate the functionality and create an additional maintenance burden, we wrapped each C++ client in a Haxl data source using Haskell’s Foreign Function Interface (FFI) so we could use it from Haskell.
Haskell’s FFI is designed to call C rather than C++, so calling C++ requires an intermediate C layer. In most cases, we were able to avoid the intermediate C layer by using a compile-time tool that demangles C++ function names so they can be called directly from Haskell.
Performance
Perhaps the biggest question here is “Does it run fast enough?” Requests to Sigma result from users performing actions on Facebook, such as sending a message on Messenger, and Sigma must respond before the action can take place. So we wanted to serve requests fast enough to avoid interruptions to the user experience.
The graph below shows the relative throughput performance between FXL and Haskell for the 25 most common types of requests served by Sigma (these requests account for approximately 95 percent of Sigma’s typical workload).
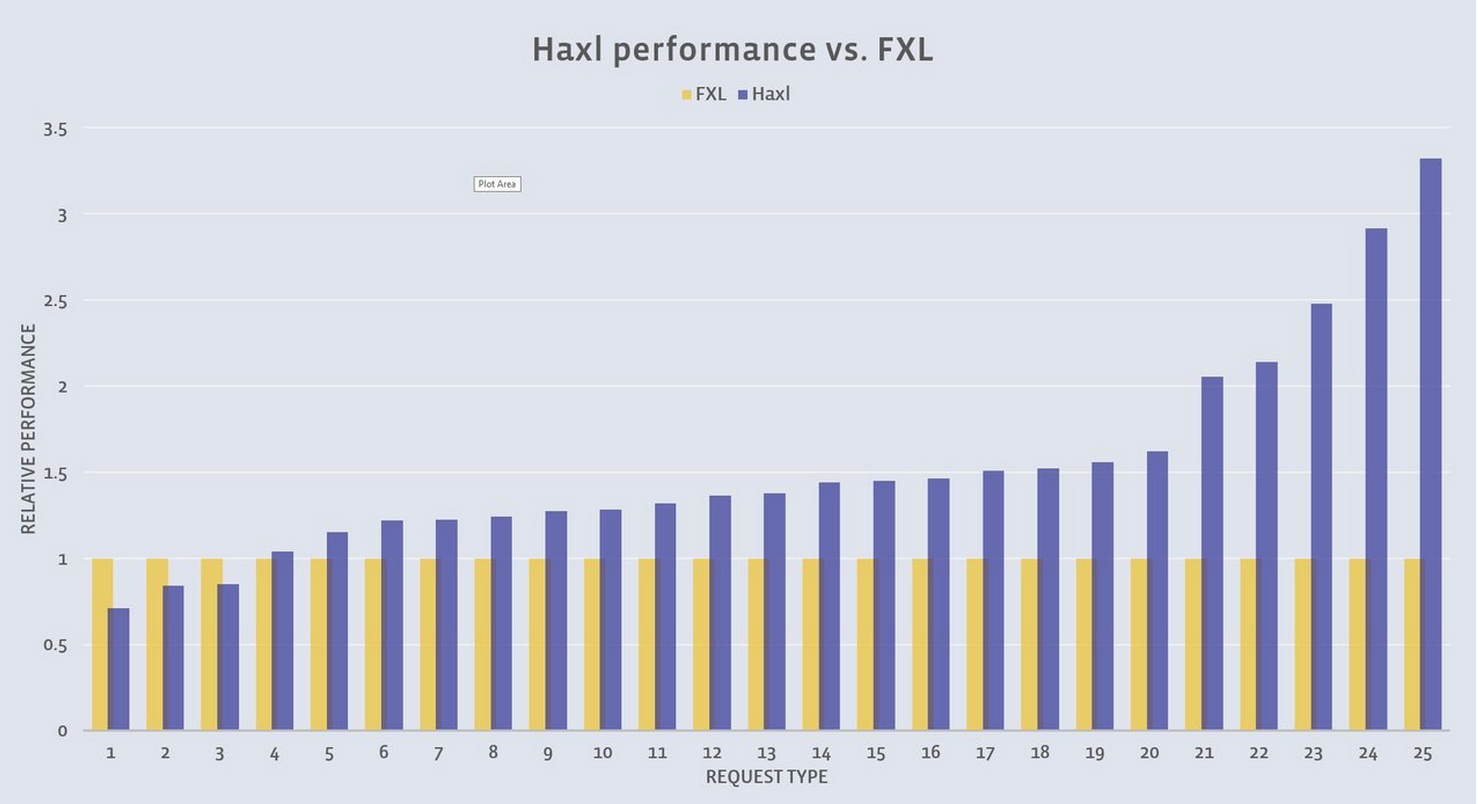
Haskell performs as much as three times faster than FXL for certain requests. On a typical workload mix, we measured a 20 percent to 30 percent improvement in overall throughput, meaning we can serve 20 percent to 30 percent more traffic with the same hardware. We believe additional improvements are possible through performance analysis, tuning, and optimizing the GHC runtime for our workload.
Achieving this level of performance required a lot of hard work, profiling the Haskell code, and identifying and resolving performance bottlenecks.
Here are a few specific things we did:
- We implemented automatic memoization of top-level computations using a source-to-source translator. This is particularly beneficial in our use-case where multiple policies can refer to the same shared value, and we want to compute it only once. Note, this is per-request memoization rather than global memoization, which lazy evaluation already provides.
- We made a change to the way GHC manages the heap, to reduce the frequency of garbage collections on multicore machines. GHC’s default heap settings are frugal, so we also use a larger allocation area size of at least 64 MB per core.
- Fetching remote data usually involves marshaling the data structure across the C++/Haskell boundary. If the whole data structure isn’t required, it is better to marshal only the pieces needed. Or better still, don’t fetch the whole thing — although that’s only possible if the remote service implements an appropriate API.
- We uncovered a nasty performance bug in aeson, the Haskell JSON parsing library. Bryan O’Sullivan, the author of aeson, wrote a nice blog post about how he fixed it. It turns out that when you do things at Facebook scale, those one-in-a-million corner cases tend to crop up all the time.
Resource limits
In a latency-sensitive service, you don’t want a single request using a lot of resources and slowing down other requests on the same machine. In this case, the “resources” include everything on the machine that is shared by the running requests — CPU, memory, network bandwidth, and so on.
A request that uses a lot of resources is normally a bug that we want to fix. It does happen from time to time, often as a result of a condition that occurs in production that wasn’t encountered during testing — perhaps an innocuous operation provided with some unexpectedly large input data, or pathological performance of an algorithm on certain rare inputs, for example. When this happens, we want Sigma to terminate the affected request with an error (that will subsequently result in the bug being fixed) and continue without any impact on the performance of other requests being served.
To make this possible, we implemented allocation limits in GHC, which places a bound on the amount of memory a thread can allocate before it is terminated. Terminating a computation safely is a hard problem in general, but Haskell provides a safe way to abort a computation in the form of asynchronous exceptions. Asynchronous exceptions allow us to write most of most of our code ignoring the potential for summary termination and still have all the nice guarantees that we need in the event that the limit is hit, including safe releasing of resources, closing network connections, and so forth.
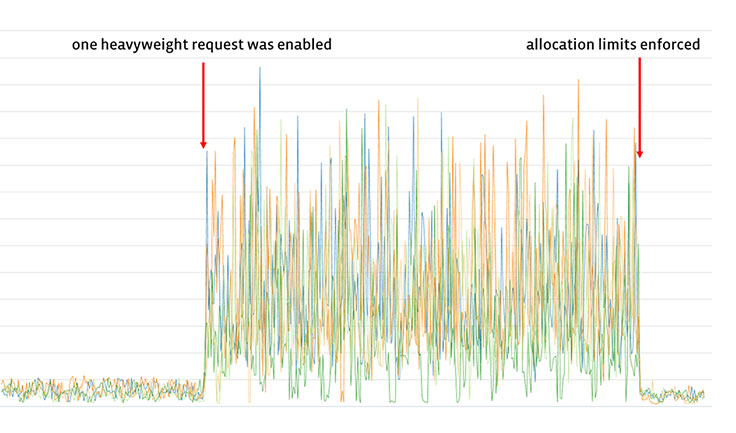
The following graph illustrates of how well allocation limits work in practice. It tracks the maximum live memory across various groups of machines in the Sigma fleet. When we enabled one request that had some resource-intensive outliers, we saw large spikes in the maximum live memory, which disappeared when we enabled allocation limits.
Enabling interactive development
Facebook engineers develop policies interactively, testing code against real data as they go. To enable this workflow in Haskell, we needed the GHCi environment to work with our full stack, including making requests to other back-end services from the command line.
To make this work, we had to make our build system link all the C++ dependencies of our code into a shared library that GHCi could load. We also customized the GHCi front end to implement some of our own commands and streamline the desired workflows. The result is an interactive environment in which developers can load their code from source in a few seconds and work on it with a fast turnaround time. They have the full set of APIs available and can test against real production data sources.
While GHCi isn’t as easy to customize as it could be, we’ve already made several improvements and contributed them upstream. We hope to make more improvements in the future.
Packages and build systems
In addition to GHC itself, we make use of a lot of open-source Haskell library code. Haskell has its own packaging and build system, Cabal, and the open-source packages are all hosted on Hackage. The problem with this setup is that the pace of change on Hackage is fast, there are often breakages, and not all combinations of packages work well together. The system of version dependencies in Cabal relies too much on package authors getting it right, which is hard to ensure, and the tool support isn’t what it could be. We found that using packages directly from Hackage together with Facebook’s internal build tools meant adding or updating an existing package sometimes led to a yak-shaving exercise involving a cascade of updates to other packages, often with an element of trial and error to find the right version combinations.
As a result of this experience, we switched to Stackage as our source of packages. Stackage provides a set of package versions that are known to work together, freeing us from the problem of having to find the set by trial and error.
Did we find bugs in GHC?
Yes, most notably:
- We fixed a bug in GHC’s garbage collector that was causing our Sigma processes to crash every few hours. The bug had gone undetected in GHC for several years.
- We fixed a bug in GHC’s handling of finalizers that occasionally caused crashes during process shutdown.
Following these fixes, we haven’t seen any crashes in either the Haskell runtime or the Haskell code itself across our whole fleet.
What else?
At Facebook, we’re using Haskell at scale to fight spam and other types of abuse. We’ve found it to be reliable and performant in practice. Using the Haxl framework, our engineers working on spam fighting can focus on functionality rather than on performance, while the system can exploit the available concurrency automatically.
For more information on spam fighting at Facebook, check out our Protect the Graph page, or watch videos from our recent Spam Fighting @Scale event.

")