Over the past few years, Facebook has been transitioning its data center infrastructure from IPv4 to IPv6. We began by dual-stacking our internal network — adding IPv6 to all IPv4 infrastructure — and decided that all new data center clusters would be brought online as IPv6-only. We then worked on moving all applications and services running in our data centers to use and support IPv6. Today, 99 percent of our internal traffic is IPv6 and half of our clusters are IPv6-only. We anticipate moving our entire fleet to IPv6 and retiring the remaining IPv4 clusters over the next few years.
Globally, however, only 15 percent of people who use Facebook have IPv6 support. So we needed a way to serve the other 85 percent who have access only to IPv4 internet while we operate an IPv6-only infrastructure within our data centers.
Traffic requests to Facebook often pass through a series of load balancers before landing on a server. Since these load balancers act as a proxy, we can let them maintain partial IPv4 support. This lets us keep everything in the data center IPv6-only while still serving IPv4 traffic.
Supporting IPv4 through load balancers
We run two software load balancers within the Facebook network: A Layer 4 load balancer (L4LB/shiv) that operates on TCP/IP, and a Layer 7 load balancer (L7LB/proxygen) that operates on HTTP/HTTPS. We took our IPv6-only data center clusters and made a series of changes to the software load balancers to tack on support for IPv4 external requests (all internal requests are IPv6-only).

All requests to Facebook enter the Facebook network through a series of network devices and are routed to a L4LB server using BGP. The L4LB announces its publicly routable virtual IP addresses (VIPs) using ExaBGP. In a dual-stacked cluster, a routable host IPv4 address is used as the BGP next-hop, but an IPv6-only server does not have this. Instead, the IPv6-only server uses an IPv4 link-local address as the BGP next-hop. This link-local address allows traffic to flow between the L4LB server and the router but avoids the need to assign the server a routable IP address.

The L4LB server then forwards the request to an L7LB through an IP tunnel. In a dual-stacked cluster, all IPv4 traffic is encapsulated in an IPv4 tunnel and all IPv6 traffic in an IPv6 tunnel. However, IPv4 tunnels are no longer possible, since neither the L4LB nor the L7LB has a routable IPv4 address. Instead, we added support for the L4LB to tunnel IPv4 traffic inside of IPv6. Our L4LB uses IPVS to forward traffic to the L7LB, but the tool we used to set up IPVS did not support mixed IP version tunnels. We created and open-sourced gnlpy, a generic netlink Python library to allow the L4LB to setup IPVS forwarding directly using Netlink.

The L7LB server receives the IPv4 client request encapsulated in an IPv6 tunnel. To process the request, the L7LB server must first decapsulate the tunnel. We previously used the default Linux tunneling modules, but these supported decapsulating only same-versioned IP tunnels. We created a custom kernel module that can decapsulate same-version or mixed-version tunnels. After the decapsulation puts the original client request on the server’s loopback interface, the L7LB receives the request as usual and is able to respond. Our L7LBs use a design called direct server return (DSR) to send the response directly to the client without going back through the L4LB. Even though the server has no routable IPv4 address, we can configure it to send IPv4 responses by setting up an IPv4 default gateway and link-local address.
Putting it all together
From a packet level, the whole flow looks like this:
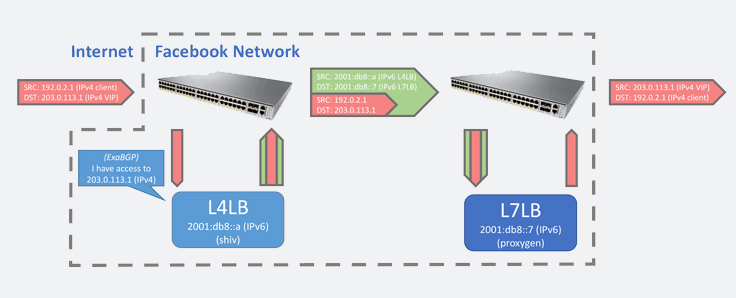
First, an IPv4 request enters the Facebook network and is routed to the L4LB. Second, the L4LB wraps the request in an IPv6 tunnel to send it to the chosen L7LB. The L4 and L7 LBs are not in the same rack, which is why the tunnel cannot use IPv4 link-local and IPv6 is required. Finally, the L7LB receives the request, decapsulates it, and sends a response directly back to the client.
While we have a few years until our IPv4 data center clusters are fully phased out, we are now in a position where we can move the rest of our infrastructure to IPv6-only without cutting off people whose internet does not yet support IPv6. And in the future, when we no longer need this feature, we can easily turn it off. We finished rolling out this support at the end of 2015, and all of our IPv6-only clusters now serve IPv4 traffic transparently.


")







