
As we continue to evolve our data infrastructure, we’re constantly looking for ways to maximize the utility and efficiency of our systems. One technology we’ve deployed is HDFS RAID, an implementation of Erasure Codes in HDFS to reduce the replication factor of data in HDFS. We finished putting this into production last year and wanted to share the lessons we learned along the way and how we increased capacity by tens of petabytes.
Background
The default replication of a file in HDFS is three, which can lead to a lot of space overhead. HDFS RAID reduces this space overhead by reducing the effective replication of data. The replication factor of the original file is reduced, but data safety guarantees are maintained by creating parity data.
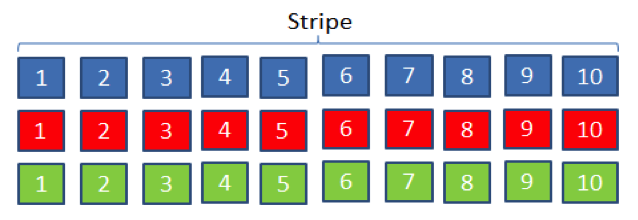
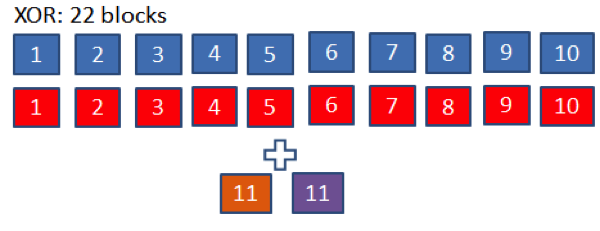
There are two Erasure Codes implemented in HDFS RAID: XOR and Reed-Solomon. The XOR implementation sets the replication factor of the file to two. It maintains data safety by creating one parity block for every 10 blocks of source data. The parity blocks are stored in a parity file, also at replication two. Thus for 10 blocks of the source data, we have 20 replicas for the source file and two replicas for the parity block, which accounts for a total of 22 replicas. The effective replication of the XOR scheme is 22/10 = 2.2.
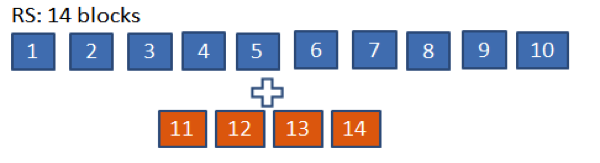
The Reed-Solomon implementation sets the replication factor of the file to one. It maintains data safety by creating four parity blocks for every 10 blocks of source data. The parity blocks are stored in a parity file at replication one. Thus for 10 blocks of the source data, we have 10 replicas for the source file and four replicas for the parity blocks, which accounts for a total of 14 replicas. The effective replication of Reed-Solomon scheme is 14/10 = 1.4
Theoretically we should be able to get 2.2x replication factor for XOR RAID files and 1.4X replication factor for Reed Solomon RAID files.
However, when we deployed RAID to production, we saved much less space than expected. After investigating, we found a significant issue in RAID, which we christened the “small file problem.”
Solving for the “small file” and other problems
The following chart shows how many physical blocks we could save by doing XOR and RS RAID for files with different numbers of logical blocks. As you can see, files with 10 logical blocks provide the best opportunity for space-saving. The fewer blocks a file has, the smaller the capacity for conservation. If a file has less than three blocks, RAID can’t save any space. We consider such un-RAID-able files “small files.” More analysis showed that in our production cluster, more than 50% of the files were small files. This meant that half of the cluster was completely un-RAID-able and was still subject to the 3x replication factor.

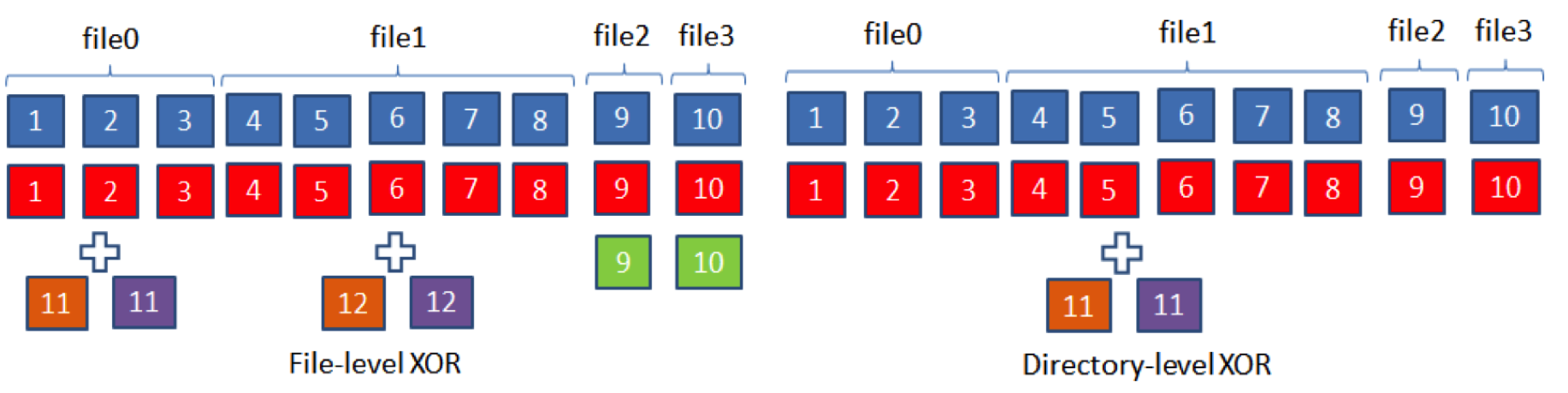
We developed directory RAID to address the small file problem based on one simple observation: In Hive, files under the leaf directory are rarely changed after creation. So, why not treat the whole leaf directory as a file with many blocks and then RAID it? In directory RAID, all the file blocks under the leaf directory are grouped together in alphabetical order, and only one parity file is generated for the whole directory. As shown below, with directory RAID, we are able to RAID file2 and file3, therefore saving more physical blocks than file-level RAID. In this way, as long as a leaf directory has more than two blocks, we are able to reclaim spaces from it, even if it’s full of small files.
A RAID node in an HDFS cluster is responsible for parity files generation and block fixing. It scans RAID policy files and generates a corresponding parity file for each source file or source directories by submitting a map/reduce job. The RAID node also periodically asks HDFS for corrupt files. For each corrupt file, it finds its corresponding parity file and fixes its missing blocks by decoding source blocks and its parity blocks. If a RAID file with missing blocks gets read, the content of the missing data will be reconstructed on the fly, thus avoiding the chance of data unavailability. We also enhance HDFS with a RAID block placement policy, placing 10 blocks of a stripe in different racks. This improves data reliability in case of rack failure.
Deploying RAID in large HDFS clusters with hundreds of petabytes of data presents a lot of challenges. Here are just a few:
- Data corruption: In the past, we’ve seen data corruption in production caused by a bug in the RAID reconstruction logic. To prevent data corruption in RAID, we decided to calculate and store CRC checksums of blocks into MySQL during RAID so that whenever the system reconstructs a missing block, it could compare the checksum of reconstructed block with the one in MySQL to verify the data correctness.
- Implementing RAID across a large directory: RAIDing a directory with more than 10,000 files in one process takes a full day to finish. If there’s any failure during the RAID process, the whole process will fail, and the CPU time spent to that point will be wasted. To solve these issues, we parallelized the RAID using a mapper-only map/reduce job, where each mapper RAIDs only a portion of the directory and produces a partial parity file. The mapper that finishes last is responsible for concatenating all partial parity files into the final parity file, which is a cheap meta operation. In this way, failure could be tolerated by simply retrying the affected mappers. With map/reduce, we are able to RAID a large directory in few hours.
- Handling directory change: Adding or deleting files could change the order of blocks under the directory. If a directory is already RAIDed, we need to re-RAID it to reflect the block order changes. The challenge is how to protect the data with stale parity before it’s replaced by new parity. In our approach, we assume a deleted file will stay in the trash directory for a few days before it’s permanently deleted, which is not uncommon in our case. As long as all the original blocks under the directory are still in HDFS, we are able to recover any of them if we know the block IDs of remaining blocks in the same stripe. Therefore, during RAID, we not only store block checksum, but we also store all the block IDs in the same stripe in MySQL. In this way, we can fix a missing block based on the original RAID order no matter how the directory has been changed. Because the re-RAID process takes only few hours before the data is purged from trash, and because Hive data directory change seldom happens, this approach works pretty well in practice.
We use different RAID policies for our Hive data stored in HDFS. New data is entered in HDFS with a replication factor of three, and most of it gets queried for analysis and reports intensively in its first day of life. After one day, it gets directory XOR RAIDed, with a reduced replication factor but still offering two copies of each byte for reading. When data becomes one month old, files under a Hive partition are compacted into RAID-friendly larger files. We choose the block size of compacted files so its number of blocks is close to a multiple of 10 blocks. They are then arrayed in a Reed-Solomon RAID. That compacted cold data ends up with a replication factor of close to 1.4.
With RAID fully rolled out to our warehouse HDFS clusters last year, the cluster’s overall replication factor was reduced enough to represent tens of petabytes of capacity savings by the end of 2013.
What’s next?
HDFS RAID is currently implemented as a separate layer on top of HDFS. RAID node is a standalone daemon responsible for file/directory RAID and block fixing. This solution presents a few problems. First, a file has to be created and then read again when RAID occurs, thus wasting network bandwidth and disk I/Os. Secondly, when files are replicated across clusters, sometimes parity files are not moved together with their source files. This often leads to data loss. Lastly, block fixing is often delayed by a delay of querying missing blocks from HDFS and the limited map/reduce slots allocated for RAID.
We are currently working on building RAID to be natively supported in HDFS. A file could be RAIDed when it is first created in HDFS, saving disk I/Os. Once deployed, the NameNode will keep the file RAID information and schedule block fixing when RAID blocks become missing, while the DataNode will be responsible for block reconstruction. This removes the HDFS RAID dependency on map/reduce.
A number of people on the Facebook Data Infrastructure team contributed to the development of Directory RAID, including Dikang Gu, Peter Knowles, and Guoqiang Jerry Chen.











