
Today, the volume of photos taken by people with smartphone cameras challenges the limits of structured categorization. It is difficult for one person to categorize their own repository of smartphone photos, much less to define a structured taxonomy for everyone’s photos.
On Facebook, people share billions of photos every day, making it challenging to scroll backward in time to find photos posted a few days ago, let alone months or years ago. To help people to find the photos they’re looking for more easily, Facebook’s Photo Search team applied machine learning techniques to better understand what’s in an image as well as improve the search and retrieval process.
Photo Search was built with Unicorn, an in-memory and flash storage indexing system designed to search trillions of edges between tens of billions of users and entities. Created a few years ago to power the social graph-aware Graph Search, Unicorn supports billions of queries per day powering multiple components in Facebook.
Graph Search was built to retrieve objects from the social graph based on the relationships between them, such as “My friends who live in San Francisco.” This has proven to be effective but presents engineering challenges when constraining the query to a relevant subset, sorting and scoring the results for relevancy, and then delivering the most relevant results. To augment this approach, the Photo Search team applied deep neural networks to improve the accuracy of image searches based on visual content in the photo and searchable text.
What search needs to understand about photos
Understanding photos at Facebook’s scale presents different challenge as compared with demonstrating low image-recognition error rates in the Imagenet Challenge competition. Applied research has produced cutting-edge deep learning techniques capable of processing billions of photos to extract searchable semantic meaning at enormous scale. Each of the public photos uploaded to Facebook is processed by a distributed real-time system called the image understanding engine.
The image understanding engine is a deep neural network with millions of learnable parameters. The engine builds on top of the state-of-the-art deep residual network trained using tens of millions of photos with annotations. It can automatically predict a rich set of concepts, including scenes, objects, animals, attractions, and clothing items. We can train models and store useful information ahead of time, which enables low-latency responses to user queries.
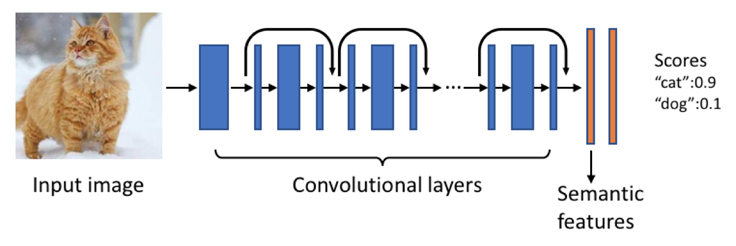
The image understanding engine produces high-dimensional float vectors of semantic features that are too computationally intensive for indexing and searching at Facebook’s scale. By leveraging iterative quantization and locality-sensitive hashing technology, the features are further compressed into a small number of bits that still preserve most of the semantics. The bit representation is used as the compact embedding of the photos that can be directly employed in ranking, retrieval, and photo deduplication. The compact embeddings rank the order of results in response to the search query. It is a similar technique applied to document search and retrieval, for which Unicorn was originally created, with different algorithms applied to the deep neural network layers specific to searching a large-scale collection of images. The object tags and semantic embeddings populate Unicorn with an index for search queries. An update to use compact embeddings for low-latency retrieval is under development.
Using tags and embeddings for modeling
A complex ranking model applied to the entire photo store is not possible given Facebook’s scale and people’s expectations for a fast response to their queries. A relevance model applied to the tags and embeddings estimates relevance and produces low-latency query results.
Concept relevance
Relevancy is assessed with rich query and photo concept signals by comparing the concept sets with a similarity function. For example, the query concepts are directly correlated to a photo’s concepts for the query “Central Park” to promote on-topic photos and remove off-topic photos during the ranking.
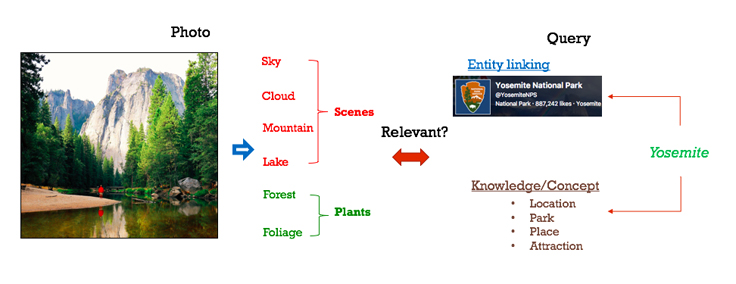
Embedding relevance
Directly measuring the concept correlation between a query and a result often is not enough to accurately predict relevance. The relevance model that was developed exploits multimodal learning to learn a joint embedding between a query and an image.
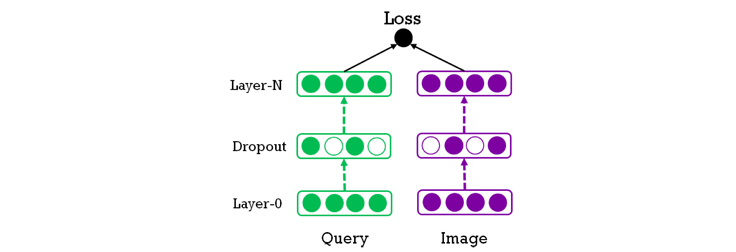
The inputs to the model are the embedding vectors of the query and the photo result. The objective of training is to minimize classification loss. Each vector is trained together and processed by several layers of a deep neural network to produce a binary signal, where a positive result denotes a match and negative one denotes a non-match. The query and photo input vectors are produced by their separate networks, potentially with a different number of layers. The networks can be trained or fine-tuned together with the parameters of the embedding layer.
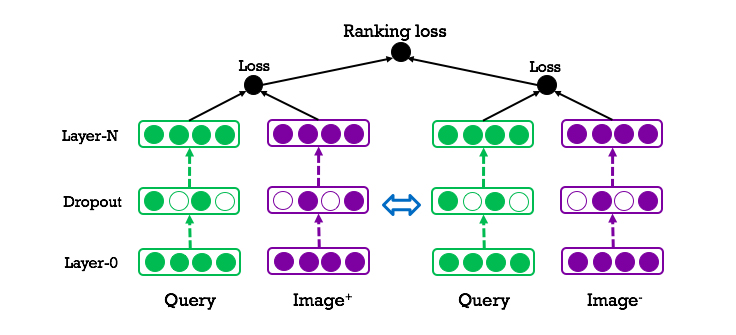
Embedding with ranking loss
The approach described above to determine relevance between a query and a photo is formulated as a classification problem. However, the main goal of the ranking is to determine the best order for the set of photo results. We went beyond classification formulation and used training with a ranking loss that processes a pair of relevant and non-relevant results for a single query at the same time.
As shown in this figure, the right part of the model is a deep copy of the left part; that is, it shares the same network structure and parameters. During training, a query and its two results are fed into the left and right components, respectively. The positive image is ranked higher than the negatively ranked image for a given query. This training strategy shows significant gains in ranking quality metrics.
Query understanding applied to Photo Search
The photo corpus is searchable with Unicorn, with the embeddings applied by the image understanding engine. The bitmap is disassociated from query and retrieval except for the index used to retrieve the photo if the query semantics applied to the embeddings produce a high probability of relevance. Some of the main signals that play a role in understanding the semantics of the query are summarized below:
Query intents suggest which types of scenes we should retrieve. For example, a query with the intent of getting an animal should show photo results with the animal as a central topic.
Syntactic analysis helps understanding a sentence’s grammatical constituents, parts of speech, syntactic relations, and semantic. Search queries usually do not observe the grammar of a written language, and existing parsers perform poorly. We use state-of-the-art techniques for training neural part of speech taggers on search queries.
Entity linking helps us identify photos about specific concepts, often represented by a page; for example, places or TV shows.
Rewriting query knowledge to extract concepts provides a semantic interpretation of a query. Concepts not only extend the query meaning but also bridge the gap between different vocabularies used by query and result.
Query embedding is a continuous vector space representation of the query. It is learned via transfer learning on top of the word2vec vector representation of words, which maps similar queries to nearby points.
Verticals and query rewriting
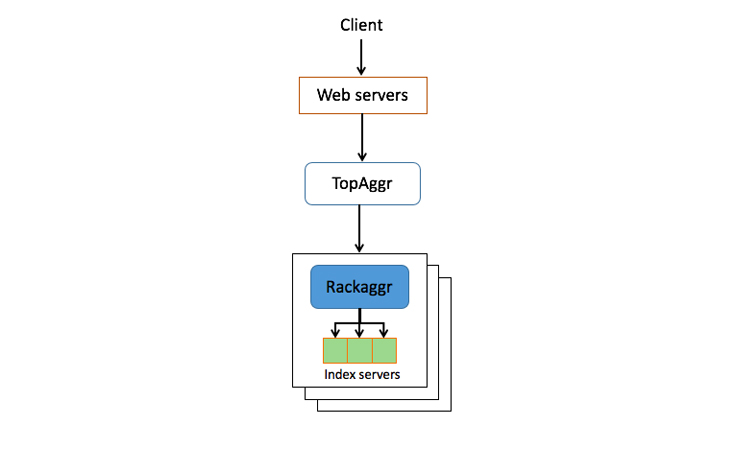
When someone types a query and hits search, a request is generated and sent to our servers. The request first goes to the web tier, which collects various contextual information about the query. The query and associated context get sent to a top aggregator tier that rewrites the query into an s-expression, which then describes how to retrieve a set of documents from the index server.
Based on the query intent, a triggering mechanism is employed using a neural network model to decide which verticals — for example, news, photos, or videos — are relevant to avoid unnecessary requests processed on less relevant verticals. For example, if a person queries the term “funny cats,” the intent would search and return more results from the photos vertical and skip querying results from the news vertical.
If a query about Halloween triggers both the intent for public photos and photos of friends in Halloween costumes, both the public and social photo verticals will be searched. Photos shared among the searcher’s friends and public photos ranked as relevant will be returned. Two independent requests are made because social photos are highly personalized and require their own specialized retrieval and scoring. Photo privacy is protected by applying Facebook’s systemwide privacy controls to the results. The diagram below depicts a module where the top section is social and the bottom is public.
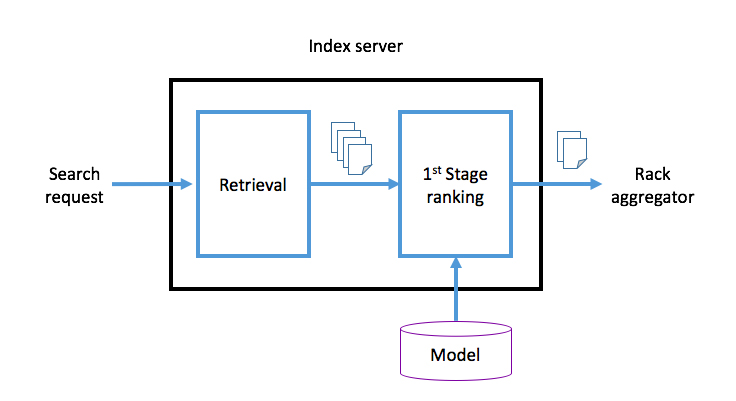
First-stage ranking
After the index servers retrieve documents according to the s-expression, the machine-learned first-stage ranker is applied to those documents. The top M documents with the highest scores are sent back to the rack aggregator tier, which performs the merge sort of all documents it receives and then returns the top N results to the top aggregator tier. The main goal of the first-stage ranking is to make sure that the documents returned to the rack aggregator preserve relevance to the query. For example, for the query “dog,” the photos with dogs should be ranked higher than those without dogs. The latency from the complexity of the retrieval and ranking stage is balanced to serve relevant photos on the order of milliseconds.
Second-stage re-ranking
After the ranked documents are returned to the top aggregator, they go through another round of signals calculation, deduplication, and ranking. The signals describing the distribution of the entire result are calculated, detecting outlying results. Next, the documents are deduplicated of visually similar results using image fingerprints. A deep neural network then scores and ranks the final order of the photo results. The collection of ranked photos, referred to as a module, is then passed to the results page UI.
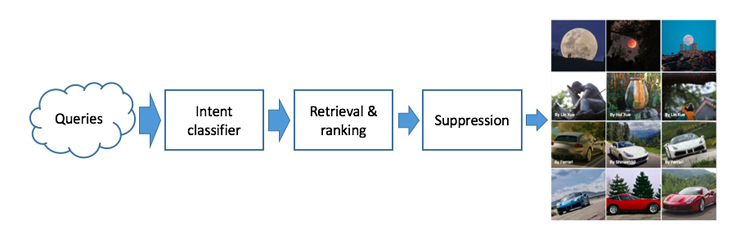
Fine-tuning relevance ranking for Photo Search
The assessment of a query’s relevance to a photo and vice versa is a core problem of Photo Search that extends beyond the scope of text-based query rewriting and matching. It requires a comprehensive understanding of the query, author, post text, and visual content of the photo result. Advanced relevance models incorporating state-of-the-art ranking, natural language processing, and computer vision techniques were developed to fine-tune the relevance of those results, giving us a novel image taxonomy system capable of delivering fast, relevant results at scale.











