
Concurrent programming is hard. It is difficult for humans to think about the vast number of potential interactions between processes, and this makes concurrent programs hard to get right in the first place. Further, concurrency errors are difficult to debug and even reproduce after they have been observed, making them time-consuming to fix.
At Facebook we have been working on automated reasoning about concurrency in our work with the Infer static analyzer. RacerD, our new open source race detector, searches for data races — unsynchronized memory accesses, where one is a write — in Java programs, and it does this without running the program it is analyzing. RacerD employs symbolic reasoning to cover many paths through an app, quickly.
Data races are one of the most basic forms of concurrency error, and removing them can help simplify the mental task of understanding a concurrent program. RacerD has been running in production for 10 months on our Android codebase and has caught over 1000 multi-threading issues which have been fixed by Facebook developers before the code reaches production. It has helped support the conversion of part of News Feed in Facebook’s Android app from a single-threaded to a multi-threaded model. We’re excited to say that RacerD is now open source, as a tool on top of our Infer static analysis platform, that will check for concurrency bugs in Java code that uses locks or @ThreadSafe annotations. In this post, we’ll discuss what RacerD does, the challenges we faced in making an effective race detector operating at scale, and the design decisions we made to cope with these challenges.
How hard is hard?
Concurrency involves different threads or activities whose executions overlap in time.
The basic reason concurrency is difficult is that when we have two streams of instructions like this, there is a fantastic number of potential schedules of execution, too many for a human or even a computer to explore. To get an idea of the scale of the challenge, say a program wanted to examine each of the different ways that two threads of 40 lines of code can interact concurrently (“interleavings,” in the jargon). Even considering those interactions at a blazing rate of 1 billion interactions per second, the computer would be working for more than 3.4 million years! On the other hand, RacerD does its work in less than 15 minutes, for much larger programs than 80 lines.
This calculation is done using the fact that the number of interleavings for 2 threads with n instructions each is the binomial coefficient C(2n, n). This is a quantity that grows extremely rapidly. For example, if we extend the number of instructions to just 150 per thread, we get over over 1088 interleavings, which is greater than the estimated number of atoms in the known universe (1080).
The inescapable conclusion is that, even though computers are powerful, we can’t explore all the possibilities by brute force.
Launching the project
Doing fast, useful concurrency analysis at scale seemed like it could be an intractable problem, well beyond the edge of static analysis knowledge as far as we were aware.
Back in 2015, one of us had stated the overall aim as follows.
I still want to understand concurrency, scalably. I would like to have analyses that I could deploy with high speed and low friction (e.g., not copious annotations or proof hints) and produce high-quality reports useful to programmers writing concurrent programs without disturbing their workflow too much. Then it could scale to many programmers and many programs. Maybe I am asking for too much, but that is what I would like to find.
Throughout 2016 we were doing research on this problem inside Facebook, creating algorithms to discover proofs of race freedom, certifications that no data race errors whatsoever could occur within a program, based on the theory of Concurrent Separation Logic. This logic lets us avoid enumerating interleavings, and thus seemed promising for tackling the scaling issue.
In late 2016, our path changed course a bit when engineers working on News Feed for Android in New York reached out to our team asking to leverage our work. They were embarking on a major project: converting part of the News Feed Android app from a sequential to a multi-threaded model. This was risky because the transformation could introduce concurrency errors. And, they were asking for the kind of analysis that we were working on, except that they wanted it yesterday and it was not nearly ready.
The technical timeline we had in mind for creating our tool for proving data race freedom was roughly 1 year for launching a proof of concept, and then further time to refine the developer experience. But our Android engineers had urgent immediate needs, they were about to embark on making part of News Feed concurrent, and this represented a golden opportunity for evolving an effective analyzer. So we decided to pivot our research, by shifting our attention from the idealized goal of eventually proving that no races could occur in vast bodies of code to the practical aim of helping people now by automatically and quickly finding many races in existing code, with high signal. We teamed up with Jingbo Yang and Benjamin Jaeger, Android engineers in Facebook’s New York office, to determine a specification of an MVP, a minimum viable product for RacerD that would serve the needs of our developers. The MVP included the following.
- High signal: detect races with low false positive rate
- Interprocedural: ability to track data races involving many nested procedure calls
- No reliance on manual annotations to specify which locks protects which bits of data
- Fast, able to report in 15 minutes on modifications to a millions-of-lines codebase, so as to catch concurrency regressions during code review
- Accurate treatment of coarse-grained locking, as used in most of product code, but no need for accurate treatment of intricate fine-grained synchronization (the minority, and changing less frequently).
The MVP was essential in determining what to focus on, and what not to focus on. For example, one of the technically most straightforward first steps in concurrency static analysis is to require that fields be guarded by annotations, and then to have the analyzer check these annotations. But while this is easy for the analysis designer, it shifts effort from the analyzer to the human and would have been a non-starter for the job of making News Feed rendering multithreaded: The Feed team needed to refactor many thousands of lines of code, and they needed to understand where there were potential concurrency issues when doing do. It would have taken many more programmers to do this manually, too many — better for the computer to perform that search.
This pivot was important in converting an intractable problem into one that we could make progress on incrementally.
In the rest of this post we’re going dive into some of the technical considerations that drove our work. First we’ll dig into the analyzer design and theory, and then change to the perspective of the end-user.
Design considerations and decisions
RacerD’s goal is to find data races. Its design is based on the following ideas:
1. Don’t do whole-program analysis; be compositional.
2. Don’t explore interleavings; track lock and thread information.
3. Don’t attempt a general, precise alias analysis; use an aggressive ownership analysis for anti-aliasing of allocated resources.
The first decision is essentially a requirement imposed by the need to run RacerD in a “move fast” deployment model where it prevents regressions at code review time. In a compositional analysis, the analysis results of parts are done without knowing about the whole. This opens the way to analyzing a code fragment (e.g., the code change under review) without knowing the context that it will run in. This is useful for checking code for thread-safety issues before placing it in a concurrent context. It’s also fairly straightforward to parallelize a compositional analysis and make it scale to big code, which is important given the size of codebases at Facebook.
The next two decisions come from observing the difficulty of balancing precision and scalability in the history of program analysis for concurrency. Our analysis differs from most previous work in that we are not aiming to prove certain absence of races, but rather (in certain circumstances) to prove their presence; we are favoring reduction of false positives over false negatives. This presents different challenges, but also allows us to make tradeoffs that would not justified if the aim were to show absence of races.
Earlier we discussed the computational difficulty of exploring interleavings in program analysis. The theory of Concurrent Separation Logic shows that we can get surprisingly far with purely sequential reasoning; it takes the extreme step of not exploring interleavings at all, instead tracking properties that are true inside and outside of locking. RacerD follows this idea using a simple boolean abstraction to track whether any lock must be held at the time of an access and whether an access must occur on the main thread. This is great for finding bugs with high confidence.
Precise alias analysis is a classically hard problem even for sequential programs. Because we focus on finding definite races, we can get away without a precise analysis for saying when arbitrary pairs of accesses may alias. But, we employ compositional ownership reasoning that gives us a minimal but important amount of anti-alias information. A cell that is owned can’t be accessed from any other thread, and thus cannot be involved in a race. After eliminating accesses to owned cells, we report conflicting accesses between cells with identical syntactic access paths (e.g., x.f.g). This can miss races that can occur via distinct access paths that refer to the same memory, but it vastly simplifies the analysis and lets us focus on finding likely races. (The RacerD documentation contains a fuller list of its limitations.)
RacerD reasoning
To illustrate some of the main features of RacerD’s reasoning, we’ll share a few examples, starting with threads and locks.
Threads and locks
The first example is motivated by a comment from the file Components.java in the Litho codebase github.com/facebook/litho:
// This [field] is written to only by the main thread with the lock held, read from the main thread with
// no lock held, or read from any other thread with the lock held.
This comment is indicative of a pattern where threading information is used to limit the amount of synchronization required. Here’s some sample code to illustrate this idea.
@ThreadSafe
class RaceWithMainThread {
int i;
void protected_write_on_main_thread_OK() {
OurThreadUtils.assertMainThread();
synchronized (this) {
i = 99;
}
}
void unprotected_read_on_main_thread_OK() {
int x;
OurThreadUtils.assertMainThread();
x = i;
}
void protected_read_off_main_thread_OK() {
int x;
synchronized (this) {
x = i;
}
}
}
Here, @ThreadSafe is taken as an instruction to the analyzer to check all non-private methods of a thread for potential races between them. If we run RacerD on this code it doesn’t find a problem.
$ infer --racerd-only -- javac RaceWithMainThread.java
..
No issues found
The unprotected read and the protected write do not race with one another because they are known to be on the same thread, as is duly recorded in their summaries.
$ infer-report
…
protected_write_on_main_thread_OK()
Accesses { ProtectedBy(both Thread and Lock) -> { Write to &this.RaceWithMainThread.i at at [line 51] } }
...
unprotected_read_on_main_thread_OK()
Accesses { ProtectedBy(Thread) -> { Read of &this.RaceWithMainThread.i at at [line 58] } }
...
On the other hand, if we include additional methods, then we get potential races.
void protected_write_off_main_thread_Bad() {
int i;
synchronized (this) {
i = 99;
}
}
void unprotected_read_off_main_thread_Bad() {
int x;
x = i;
}
RaceWithMainThread.java:77: error: THREAD_SAFETY_VIOLATION
Read/Write race. Non-private method `RaceWithMainThread.unprotected_read_off_main_thread_Bad` reads from `RaceWithMainThread.i`. Potentially races with writes in methods `{ void RaceWithMainThread.protected_write_off_main_thread_Bad(),
void RaceWithMainThread.protected_write_on_main_thread_OK() }`.
75. void unprotected_read_off_main_thread_Bad() {
76. int x;
77. > x = i;
78. }
79.
RaceWithMainThread.java:58: error: THREAD_SAFETY_VIOLATION
Read/Write race. Non-private method `RaceWithMainThread.unprotected_read_on_main_thread_OK` reads from `RaceWithMainThread.i`. Potentially races with writes in method `void RaceWithMainThread.protected_write_off_main_thread_Bad()`.
56. int x;
57. OurThreadUtils.assertMainThread();
58. > x = i;
59. }
60.
Fine-grained concurrency
For our next example, let’s look at some fine-grained concurrency.
If we run this:
@ThreadSafe
public class DCL {
private Object o;
public Object LazyInit(){
if (o == null) {
synchronized (this){
if (o == null) {
o = new Object();
}
}
}
return o;
}
}
RacerD finds a bug:
DCL.java:36: error: THREAD_SAFETY_VIOLATION
Read/Write race. Non-private method `DCL.LazyInit` reads from `DCL.o`. Potentially races with writes in method `Object DCL.LazyInit()`.
35. }
36. > return o;
37. }
This bug is in fact a classic one in Java, called double-checked locking. The fix is to mark o volatile, and then RacerD doesn’t report.
RacerD has caught bugs of this form which were then fixed before reaching production in Facebook code. However, there are related bugs that it does not find. If we remove the inner if statement but maintain the volatile, then we still have a race. But Infer does not report: a false negative.
Recall above our determination to go after coarse-grained locking errors but not fine-grained. The semantics of volatile is quite complicated, so if you mark a field volatile we assume you know what you’re doing and don’t report any races. We have made the decision in RacerD not to report on any volatile races: to treat volatile accurately would. This is a stunningly effective heuristic, since it’s almost always the volatile part of double-checked locking that folks get wrong, not the guards.
It is not that an accurate treatment of volatile is unthinkable, but rather that we have decided there are higher priority items in developing an analyzer to serve the developers. This decision illustrates our point 5 in the MVP specification above, on avoiding fine-grained concurrency at first. It is a compromise taken in order to make progress, and can be revisited.
For ease of exposition, all of the examples we have shown involve races between one or two procedures that directly access the data in question. In practice, races often occur between two procedures that access data indirectly via a deep chain of calls. Indeed, interprocedural reasoning was one of the first request of Facebook engineers, because often the root of a tree used in the representation of a user interface is in one class but mutations happen several layers down the call stack in a different class. See the website for further information on interprocedural data races.
Ownership
Ownership tracking in our abstract domain helped make the analysis high signal. The core problem is that we might have identical-looking accesses that nonetheless do not race because they involve a newly allocated object.
Here is a class that shows the basic issues:
@ThreadSafe
class Ownership {
int x;
Ownership oo = new Ownership();
void unprotected_owned_write() {
Ownership o = new Ownership();
o.x = 88;
}
void unprotected_unowned_write() {
Ownership o = oo;
o.x = 99;
}
}
In the first case, the write o.x = 88 is to a field of a newly allocated object, and no process can race with it. In the second case, the write o.x = 99 is actually a write to a field of object oo, and it can race with other processes; in particular, there is a self-race if this method is run in parallel with itself.
RacerD tracks ownership, and is aggressive about deleting accesses to owned objects. For example, the summary of unprotected_owned_write() does not record any accesses whatsoever.
We want to be clear that while the approach of deleting owned accesses is great for our primary goal of limiting false positives, it can also lead to false negatives. Consider:
@ThreadSafe
public class PointerTransferringBuffer {
A contents;
public void m0() {
A newa = new A();
synchronized(this){
contents = newa;
}
newa.data = 88;
}
public void m1() {
A transferreda;
ThreadUtils.assertMainThread();
synchronized(this){
transferreda = contents;
}
//assertMainThread rules out the self race
transferreda.data = 99;
}
}
Here, the assignments newa.data = 88 and transferreda.data = 99 race with one another, but RacerD fails to report; the reason is that the accesses to newa.data is dropped from m0()‘s summary.
On the other hand if the assignment to newa.data is deleted from the program and not just the summary, then we have a safe program exhibiting the phenomenon of ownership transfer. It is not impossible for automated techniques to deal accurately with examples such as this. Indeed, Concurrent Separation Logic proves programs like this one, and tools based on it (e.g., Smallfoot) can certify race freedom. The Rust programming language also has typing rules to deal with ownership transfer. However, the cost in these cases is an additional level of annotations, which in effect tell the analyzer information about objects that transfer.
Ownership transfer examples like this one do occur inside Facebook’s Java code, for example in ComponentTree.java from github.com/facebook/litho, but they tend to appear in framework rather than product code (the majority). Our priority has been to serve the majority first (again illustrating point 5 from the MVP), but we are planning on on incorporating ownership transfer into a future version of our analyzer.
Deployment
RacerD is implemented as a specialized program analysis using the Infer.AI analysis framework. The framework provides an API to Infer’s backend compositional analysis infrastructure, based on abstract interpretation. You describe an “abstract domain,” symbolic values for the analysis to track, a way to transform these values by program statements, and a way to make a specification or “summary” of a procedure that independent of its program parts. Given this, out pops a program analysis that works compositionally and can (often) scale to big code.
Infer is used at Facebook in both a batch-mode deployment and as a bot participating in code review. In the batch deployment developers, often ones specifically interested in catching thread safety errors before placing code into a concurrent context, run RacerD on a class and resolve as many warnings as possible. In the deployment for code review Infer runs as part of the Facebook continuous integration (CI) system. For each code change a developer submits, the CI runs Infer alongside other jobs for compilation and testing. This deployment applies to all Android developers, whether they are thinking about concurrency or not, and is aimed at catching threading regressions: Infer only reports bugs that were introduced by each code change.
All told, hundreds of classes have been checked in the batch mode deployment, and over 1,000 analyzer issues have been addressed in batch and CI combined (with the majority being CI). The issues addressed divide between non-functional changes where annotations are added that document threading assumptions and functional changes that avoid races, with each category having seen fixes numbering in the hundreds.
In order for Infer to be effective as part of the CI, the analysis must report issues quickly and use resources efficiently. We have found compositional analysis essential for meeting these requirements. With a whole-program analysis, the only obvious way to analyze a code change is to reanalyze the entire app. On a machine much more powerful than the ones used in the CI, running Infer on the Facebook Android app takes about 130 minutes. On code changes, Infer can run much faster. The graph below shows the distribution of Infer running times on a code changes over a one week period.
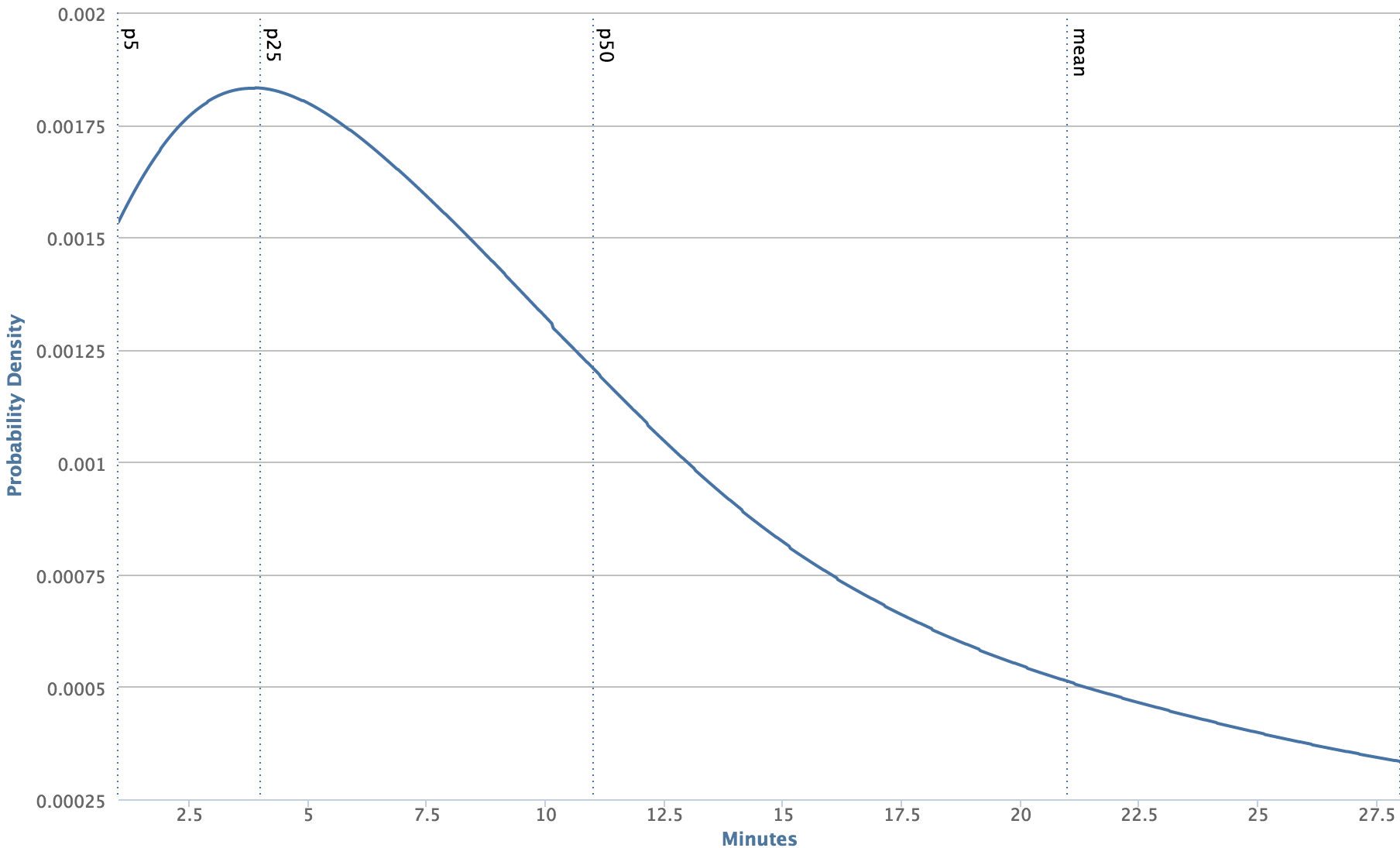
We can see that an average code change is analyzed in less than 12 minutes, well over 10 times faster than analyzing the entire app! This is possible thanks to the combination of compositional analysis and the distributed cache of Facebook’s Buck build system, a cache that Infer piggybacks on.
Conclusion
Reasoning about concurrency has been studied for over 40 years and has seen many research advances. However, not much of the work has made it through to deployment where it can help programmers in their daily jobs. (See here for discussion of some of the related research context).
RacerD demonstrates that a static concurrency analysis can be developed and effectively applied at the speed and scale demanded by Facebook’s development model, where a large codebase is undergoing frequent modification. The analysis has a high degree of automation, where the relationship between threads, locks and memory is discovered rather than specified by a person; this means that it can immediately scale to many programmers with low friction. Without these characteristics — speed, scale and low friction — the application supporting News Feed, where >1,000 issues were addressed before code was placed in a concurrent context, would not have been viable.
Concurrency in general remains a fundamental and difficult problem area, but these results make us hopeful: with sufficient innovation, more techniques and tools might be developed that will further help working programmers in the challenging task of engineering concurrent systems.











