
At Facebook, we have unique storage scalability challenges when it comes to our data warehouse. Our warehouse stores upwards of 300 PB of Hive data, with an incoming daily rate of about 600 TB. In the last year, the warehouse has seen a 3x growth in the amount of data stored. Given this growth trajectory, storage efficiency is and will continue to be a focus for our warehouse infrastructure.
There are many areas we are innovating in to improve storage efficiency for the warehouse – building cold storage data centers, adopting techniques like RAID in HDFS to reduce replication ratios (while maintaining high availability), and using compression for data reduction before it’s written to HDFS. The most widely used system at Facebook for large data transformations on raw logs is Hive, a query engine based on Corona Map-Reduce used for processing and creating large tables in our data warehouse. In this post, we will focus primarily on how we evolved the Hive storage format to compress raw data as efficiently as possible into the on-disk data format.
RCFile
Data that is loaded into tables in the warehouse is primarily stored using a storage format originally developed at Facebook: Record-Columnar File Format (RCFile). RCFile is a hybrid columnar storage format that is designed to provide the compression efficiency of a columnar storage format, while still allowing for row-based query processing. The core idea is to partition Hive table data first horizontally into row groups, then vertically by columns so that the columns are written out one after the other as contiguous chunks.
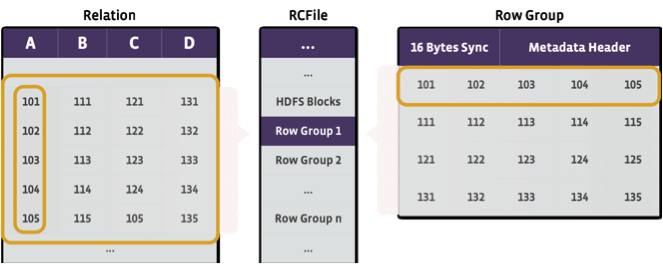
Figure 1: RCFile – Each table consists of row groups that are laid out in a columnar fashion on disk
When the columns in a row group are written to disk, RCFile compresses each column individually using a Codec like Zlib/Lzo. The reader uses lazy decompression of columns, so if the user runs a query over a subset of columns in a table, RCFile skips decompression and deserialization of the columns that are not needed. On average, RCFile provided us 5x compression over a representative sample of raw data stored in our data warehouse.
Beyond RCFile: What was next?
As the volume of data stored in our warehouse continued to grow, engineers on the team began investigating techniques to improve compression efficiency. The investigations focused on column-level encodings such as run-length encoding, dictionary encoding, frame of reference encoding, and better numeric encodings to reduce logical redundancies at the column level prior to running it through a codec. We also experimented with new column types (for example: JSON is used very heavily across Facebook, and storing JSON in a structured fashion allows for efficient queries as well as removing common JSON metadata across column values). Our experiments indicated that column-specific encodings (when applied judiciously) could provide significant improvements in compression over RCFile.
Around the same time, HortonWorks had also begun investigating similar ideas for an improved storage format for Hive. The HortonWorks engineering team designed and implemented ORCFile’s on-disk representation and reader/writer. This provided us a great starting point for a new storage format for the Facebook data warehouse.
ORCFile: The details
When Hive writes table data to disk in the ORCFile format, the data is partitioned into a set of 256 MB stripes. A stripe is similar to a row group in RCFile – but within each stripe, ORCFile uses encoding techniques on the column values and then compresses the columns using a codec like Zlib. String columns are dictionary encoded and the column encoding is performed over all the rows in a stripe. Further, ORCFile stores an index for every 10,000 rows in each stripe and the corresponding minimum and maximum values per column; this allows for query optimizations such as skipping over a set of rows when applying column filters.
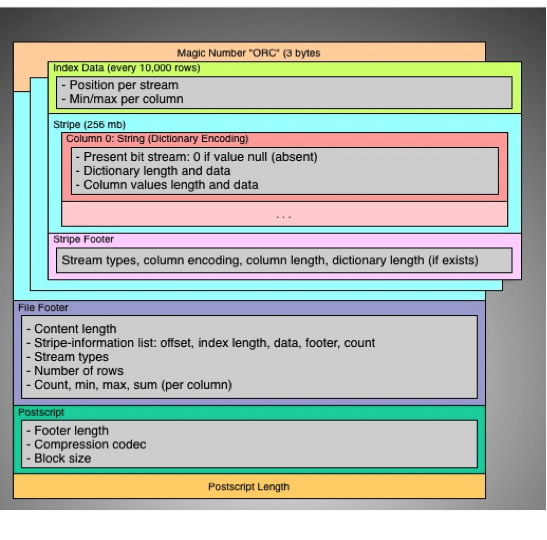
Figure 2: ORCFile on-disk representation
Apart from compression improvements, a significant benefit of the new storage format is that columns and rows are indexed into with offsets, removing the need for separators to delimit things such as the end of a row. RCFile, on the other hand, reserves certain ASCII values as separators and requires escaping these values in the data stream. Additionally, query engines can leverage stripe and file-level metadata per column to improve query efficiency.
Adaptive column encodings
When we started testing ORCFile on data sets in our warehouse, we found that it caused some tables to bloat and some to compress well, leading to a negligible improvement in compression across a representative set of tables in our warehouse. Dictionary encoding can cause bloat when column entropy is high, so applying dictionary encoding by default on all string columns did not work well. We considered two approaches to pick the columns to dictionary encode in each table: statically determine this based on user-specified column metadata, or dynamically adapt the encoding technique based on observed column values at runtime. We opted for the latter since it scales better to the very large number of existing tables in our warehouse.
We ran many experiments to identify heuristics that maximize compression without impacting ORCFile write performance. Strings dominate the largest tables in our warehouse and make up about 80% of the columns across the warehouse, so optimizing compression for string columns was important. By using a threshold on observed number of distinct column values per stripe, we modified the ORCFile writer to apply dictionary encoding to a stripe only when beneficial. Additionally, we sample the column values and take the character set of the column into account, since a small character set can be leveraged by codecs like Zlib for good compression and dictionary encoding then becomes unnecessary or sometimes even detrimental if applied.
For large integer types, we had a choice to run-length encode or dictionary encode. Run-length encoding proved marginally better than using a codec in most cases, whereas dictionary encoding performed well when there was a low number of distinct values. Based on the results, we implemented dictionary encoding instead of run-length encoding on large integer columns. The combination of these heuristics across strings and numeric values had a big impact on the compression efficiency of ORCFile.
We experimented with several other techniques to improve compression. A noteworthy idea that we investigated was adaptive run length encoding, which uses heuristics to apply run length encoding only when beneficial. There was also work in open source to adaptively choose between multiple encodings for integers. Unfortunately these changes regressed write performance, despite the compression improvements. We also investigated the effect of stripe size on compression. Surprisingly, increasing the stripe size had a negligible impact on compression. As the stripe size increased, so did the number of dictionary entries, and this in turn increased the number of bytes needed for the encoded column values. So it turned out that storing fewer dictionaries was not as beneficial as we had expected — empirically, a stripe size of 256 MB was the sweet spot.
Write performance
Given that data write speed can affect query performance at our scale, we made a variety of changes to the open source ORCFile writer for better write performance. The key ideas were to eliminate redundant or unnecessary work, and to optimize memory usage.
One key change we made is in how the Facebook ORCFile writer creates sorted dictionaries. To achieve dictionary sorting, the open source ORCFile writer maintains the dictionary in a red-black tree. However, with adaptive dictionary encoding, even when a column was not a suitable candidate for dictionary encoding, it would take the O(log(n)) performance hit of inserting each distinct key into the red-black tree. By using a memory-efficient hash map for the dictionary, and sorting only when necessary, we reduced the memory footprint of the dictionary by 30% — and, more importantly, improved write performance by 1.4x. The dictionary was initially stored as an array of byte arrays for fast, memory-efficient resizing. However, this made dictionary element access (which is a frequent operation) a hotspot. We opted to use Slice from the Airlift library for the dictionary instead, and improved writer performance by another 20% – 30%.
Turning on dictionary encoding per column is compute intensive. Since column characteristics tend to repeat across stripes, we recognized that there was limited benefit to dictionary encoding for every stripe. So we changed the writer to determine column encoding based on a subset of stripes and repeat that encoding in subsequent stripes. This meant that if the writer determined that dictionary encoding the values was not beneficial, the subsequent stripes would intelligently skip dictionary encoding altogether. Because of the improved compression efficiency of Facebook ORCFile format, we were also able to lower the Zlib compression level used and get a 20% improvement in write performance with minimal impact on compression.
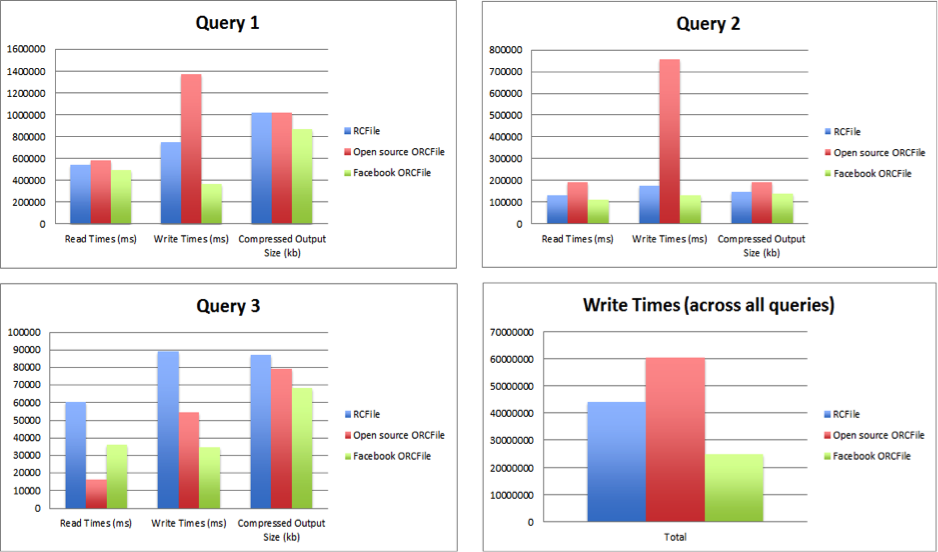
Figure 3: Performance comparisons on 175 query benchmark
Read performance
Turning to read performance, one feature that we quickly noticed a need for was lazy column decompression. Consider a query that selects many columns when performing a very selective filter on one column. Without lazy decompression, all the data for every column read by the query is decompressed. Ideally, only data for the rows that pass the filter would be decompressed and decoded so the query isn’t spending a majority of its time decompressing and decoding data that never gets used.
To support this, we added lazy decompression and lazy decoding to the Facebook ORCFile reader by leveraging the index strides that already existed in the format. In the case described above, all the rows for the column the filter is operating on will be decompressed and decoded. For the other columns of the rows that pass the filter, we changed the reader to seek to the appropriate index stride in the stripe (a metadata operation) and only decompress and decode the values preceding and including the target row in that index stride. On our tests, this makes selective queries on Facebook ORCFile run 3x faster than open source ORCFile. Facebook ORCFile is also faster than RCFile for these very selective queries because of the addition of lazy decoding to the format.
Summary
By applying all these improvements, we evolved ORCFile to provide a significant boost in compression ratios over RCFile on our warehouse data, going from 5x to 8x. Additionally, on a large representative set of queries and data from our warehouse, we found that the Facebook ORCFile writer is 3x better on average than open source ORCFile.
We have rolled out this new storage format to many 10s of petabytes of warehouse data at Facebook and have reclaimed 10s of petabytes of capacity by switching from RCFile to Facebook ORCFile as the storage format. We are in the process of rolling out the format to additional tables in our data warehouse, so we can take further advantage of the improved storage efficiency and read/write performance. We have made our storage format available at GitHub and are working with the open source community to incorporate these improvements back into the Apache Hive project.
What’s next?
We have many ideas on how to further improve compression and reader/writer performance in ORCFile. These ideas include supporting additional codecs such as LZ4HC, using different codecs and compression levels for different columns when encoded differently, storing additional statistics and exposing these to query engines, and pulling in work from open source such as predicate pushdown. We also have several other ideas to further improve storage efficiency for our warehouse. This includes eliminating logical redundancies across source and derived tables, sampling for cold data sets, and augmenting the Hive type system with additional commonly needed types that are currently stored as strings.
A number of people on the Facebook Analytics Infrastructure team contributed to the above work on ORCFile, including the authors of this post: Pamela Vagata, Kevin Wilfong and Sambavi Muthukrishnan. Thanks to HortonWorks for collaborating with us on building a better storage format for Hive.











