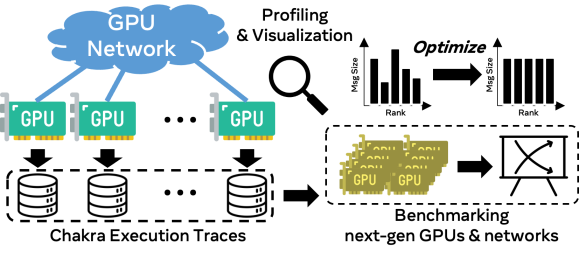
This post introduces Wangle, a C++ library for building protocols, servers, and clients in an asynchronous, clean, composable, and scalable manner. Wangle is heavily influenced by the JVM-based libraries Netty, a Java network application framework, and Finagle, a Scala RPC system built at Twitter on top of Netty. Wangle aims to provide a similar set of abstractions for C++ as the combination of Netty and Finagle does for the JVM. Wangle has been open-sourced since summer 2015 and is a stable component of several Facebook projects, including the open source fbthrift and Proxygen. We’ll give a brief overview of the core Wangle components and then walk through an example to demonstrate their power. Note that we’ll focus on the Netty-like components and leave the Finagle-like pieces to a later post.
Asynchronous building blocks
Wangle builds on top of two other Facebook-developed libraries that provide asynchronous interfaces, both of which live in Folly, our open source C++ library.
First is folly/io/async, a set of object-oriented asynchronous IO wrappers around libevent. Folly/io/async provides event bases, sockets (including TCP sockets, UDP sockets, server sockets, and SSL sockets), and async timeout/callback interfaces, among other things.
Second are Futures, an implementation of the Promise/Future pattern for C++11. Futures provide a monadic pattern for expressing asynchronous computations that is simultaneously performant, clean, and composable.
Concurrency framework
Thread pools
Wangle provides a set of useful concurrency primitives, the most important of which are a pair of thread pool implementations — CPUThreadPoolExecutor and IOThreadPoolExecutor. It is useful to separate IO-bound work (e.g., asynchronous socket IO) from CPU-bound work (e.g., application business logic) for a couple of reasons.
First, in event-driven server environments like Wangle’s, M connections are typically multiplexed across N IO threads for M >> N, since one thread per connection does not scale effectively (see the C10K problem). It is important, then, that those threads block as little as possible, because every cycle spent on one connection’s work blocks all the other connections hosted on that thread. Therefore, applications should strive to relocate long-running work or blocking operations to a separate CPU-bound thread pool in order to reduce tail latency. Wangle makes this easy, as we’ll see later on in our example.
Second, thread pools can be optimized for either CPU-bound or IO-bound workloads, which is why we have separate implementations for each. For IO pools, the threads cannot share a single epoll file descriptor, as epoll_wait() wakes up all waiters on an active event, which would lead to contention on processing the event. Instead, each thread has its own epoll fd and thus its own task queue. This precludes fair scheduling, as there is no way for the epoll_wait() calls to cooperate — we employ round-robin scheduling instead.
For CPU pools, we can do better. Threads wait on a last-in first-out (LIFO) semaphore to pull tasks from a multiproducer, multiconsumer, lockless shared queue. A LIFO semaphore has several desirable performance characteristics. First, the LIFO policy means that as few threads as possible are actively processing tasks, leading to increased cache locality. Second, our implementation madvises away the stacks of inactive threads, meaning that CPU pools can be sized quite liberally without excess memory usage. Additionally, our CPU pool supports task priorities via multiple shared queues.
Both thread pools provide a host of useful features, including per-pool and per-task statistics, pool resizing, task expiration (including CoDel expiration), custom thread factories, and thread event observers.
Global executors
A common anti-pattern that we have observed at Facebook is for shared components to spin up their own thread pools for their own work. Complex applications might use a multitude of such components, and all of a sudden there is a gross excess of (likely idle) threads lying around. Wangle provides a simple GlobalExecutor abstraction to encourage moving away from this pattern. Using Folly’s Singleton implementation, we provide access to global, overridable, and lazily created IO and CPU thread pools via getIOExecutor() and getCPUExecutor(), respectively. Users get easy access to the executors while avoiding the overhead and code complexity of self-managed executors.
Pipelines and codecs — sending your socket data through a series of tubes
Pipelines are a core concept in Netty that we have adapted in Wangle. The basic idea is to conceptualize a networked application as a series of handlers that sit in a pipeline between a socket and the application logic. Bytes are read from the socket and passed through the handlers, possibly getting transformed into protocol-specific messages by a special handler called a codec. Eventually the message makes it way to the application, where it is processed and where any replies are sent back through the pipeline to the socket. Other inbound and outbound events such as read errors, read EOFs, connection closures, and socket status changes supplement data read/write events. Handlers are free to intercept any subset of these events and react accordingly. The following is a partial list of built-in handlers that demonstrate the concept.
- AsyncSocketHandler typically sits at the bottom of a pipeline and handles the actual IO on the connection, pushing inbound bytes up the pipeline and writing outbound bytes to the socket.
- OutputBufferingHandler buffers writes such that they are flushed once per event loop, thereby minimizing syscalls.
- EventBaseHandler reschedules outbound events onto the connection’s IO thread so that upstream handlers can write or close from any thread (inbound events always start on the IO thread).
- FixedLengthFrameDecoder splits inbound bytes into fixed-length frames.
- LineBasedFrameDecoder splits inbound bytes on customizable line delimiters.
- LengthFieldBasedFrameDecoder splits inbound bytes based on a length field.
- LengthFieldPrepender prepends a length field to outbound bytes. This is the inbound counterpart to LengthFieldBasedFrameDecoder.
- StringCodec is a codec that simply converts inbound bytes into strings and outbound strings into bytes.
For instance, our example Telnet server has a pipeline that looks like this:
AsyncSocketHandler ↔ LineBasedFrameDecoder ↔ StringCodec ↔ TelnetHandler
Handlers can be reused in multiple pipelines. The binding between a handler and a pipeline is represented by a HandlerContext, which is passed into every handler callback.
Bootstrapping servers and clients
Pipelines are a great way of modeling a single connection on either the client or server side. But how do we create and manage these connections on either side? Enter ServerBootstrap and ClientBootstrap, Wangle’s facilities for easily creating and configuring pipeline-based servers and clients.
In addition to its other features, ServerBootstrap allows you to:
- Create a server.
- Provide a factory for connection pipelines.
- Specify separate IO thread pools for accepting connections (multiple accept threads are supported via SO_REUSEPORT) and for handling connection IO.
- Bind to and start accepting on a port.
- Stop the server.
Here’s a snippet from our Telnet example that exercises the most basic features.
ServerBootstrap<TelnetPipeline> server;
server.childPipeline(std::make_shared<TelnetPipelineFactory>());
server.bind(FLAGS_port);
server.waitForStop();
ClientBootstrap<TelnetPipeline> client;
client.group(std::make_shared<folly::wangle::IOThreadPoolExecutor>(1));
client.pipelineFactory(std::make_shared<TelnetPipelineFactory>());
auto pipeline = client.connect(SocketAddress(FLAGS_host, FLAGS_port)).get();
// ... do Telnet-y things (to wit, read from stdin and write to the pipeline)...
pipeline->close();
Building a file streaming server with Wangle
Now let’s use the above building blocks to construct a complete working example. In this case, we’re going to build a simple server that takes server-side file paths as input and streams the contents of the file back to the client. We’ll utilize the global CPU pool to perform the blocking disk reads to avoid clogging up the IO threads. First, let’s put together the application handler that will sit at the top of our pipelines:
using namespace folly;
using namespace wangle;
// This handler sits above a StringCodec and therefore has std::string
// as its input and output type
class FileServerHandler : public HandlerAdapter<std::string> {
public:
// The handler's core: handling a file request, specified by string
// The handler is shared by all client pipelines. Context objects represent
// the binding between a handler and a pipeline and enable a handler to
// interact with a specific pipeline.
void read(Context* ctx, std::string filename) override {
// Close the connection on 'bye'
if (filename == "bye") {
close(ctx);
}
// Open up the local file
int fd = open(filename.c_str(), O_RDONLY);
if (fd == -1) {
write(ctx, sformat("Error opening {}: {}\r\n",
filename,
strerror(errno)));
return;
}
// Stat the local file
struct stat statBuf;
if (fstat(fd, &statBuf) == -1) {
write(ctx, sformat("Could not stat file {}: {}\r\n",
filename,
strerror(errno)));
return;
}
// Offload our blocking disk read work to the global CPU pool
// with the via() feature of Futures
via(getCPUExecutor(), [this, ctx, statBuf, filename]{
// Since we're dealing in raw file bytes, we want to bypass the
// StringCodec and write directly to the downstream EventBaseHandler,
// which will pass off the write to the IO thread and then on down to
// the socket.
auto writeCtx = ctx->getPipeline()->getContext<EventBaseHandler>();
auto rawBuf = malloc(FLAGS_chunk_size);
size_t totalBytesRead = 0;
while (totalBytesRead < statBuf.st_size) {
size_t toRead = std::min(statBuf.st_size - totalBytesRead,
(uint64_t)FLAGS_chunk_size);
auto buf = IOBuf::wrapBuffer(rawBuf, FLAGS_chunk_size);
// Perform the blocking read
auto bytesRead = ::read(fd, buf->writableData(), toRead);
if (bytesRead < 0) {
write(ctx, sformat("Error reading file {}: {}\r\n",
filename,
strerror(errno)));
return;
}
totalBytesRead += bytesRead;
buf->trimEnd(buf->length() - bytesRead);
try {
// Write file bytes directly to the EventBaseHandler and block
// on the result.
writeCtx->getHandler()->write(writeCtx, std::move(buf)).get();
} catch (const std::exception& e) {
// Stop file transfer on a write error
write(ctx, sformat("Error sending file {}: {}\r\n",
filename,
exceptionStr(e)));
return;
}
}
});
}
// This event fires on an inbound IO error. Try to write an error back to
// the client and then close the connection.
void readException(Context* ctx, exception_wrapper ew) override {
write(ctx, sformat("Error: {}\r\n", exceptionStr(ew))).ensure([this, ctx]{
close(ctx);
});
}
// This event fires once a connection is open for IO. Let's welcome the user.
void transportActive(Context* ctx) override {
SocketAddress localAddress;
ctx->getTransport()->getLocalAddress(&localAddress);
write(ctx, "Welcome to " + localAddress.describe() + "!\r\n");
write(ctx, "Type the name of a file and it will be streamed to you!\r\n");
write(ctx, "Type 'bye' to exit.\r\n");
}
};
Once we have our application handler defined, we need to specify a pipeline factory that will be invoked on every new connection. Given a connection in the form of an AsyncSocket, the factory creates and adds handlers to a pipeline that will process the connection thereafter. In this case, we’ll need a socket handler, a handler that moves writes to the IO thread (because we perform writes from the CPU pool above), a line-based frame decoder, a simple string codec, and finally our FileServerHandler:
// Pipelines are templated on their input and output types. Our server pipelines
// read IOBufQueues off the socket and end in a string handler.
typedef Pipeline<IOBufQueue&, std::string> FileServerPipeline;
// We'll pass this pipeline factory to our server, which will invoke it on every
// new connection, passing a pointer to the AsyncSocket for that connection.
class FileServerPipelineFactory : public PipelineFactory<FileServerPipeline> {
public:
FileServerPipeline::UniquePtr newPipeline(std::shared_ptr<AsyncSocket> sock) {
FileServerPipeline::UniquePtr pipeline(new FileServerPipeline);
// Handles socket IO
pipeline->addBack(AsyncSocketHandler(sock));
// Ensures writes are performed on the IO thread
pipeline->addBack(EventBaseHandler());
// Splits incoming bytes into line-delimited frames, Telnet-style
pipeline->addBack(LineBasedFrameDecoder());
// Converts inbound bytes (IOBufs) to strings and outbound strings to bytes
pipeline->addBack(StringCodec());
// Finally, our application handler
pipeline->addBack(&fileServerHandler_);
// Glue it all together. Among other things, checks to make sure types are
// lined up correctly.
pipeline->finalize();
return std::move(pipeline);
}
private:
// Reuse the same FileServerHandler in all client pipelines
FileServerHandler fileServerHandler_;
};
Finally, let’s set up a server based on the above PipelineFactory, bind to a port, and begin accepting connections:
int main(int argc, char** argv) {
google::ParseCommandLineFlags(&argc, &argv, true);
// Bootstraps are templated on the pipeline type
ServerBootstrap<FileServerPipeline> server;
// Provide our pipeline factory
server.childPipeline(std::make_shared<FileServerPipelineFactory>());
// Bind and begin accepting on the provided port
server.bind(FLAGS_port);
// Wait for another thread to call stop()
server.waitForStop();
return 0;
}
That’s it! We now have a basic file server in fewer than 200 lines of code. Please note that Wangle has a more efficient implementation of file transfer built in. FileRegion implements zero-copy asynchronous file transfer from a file descriptor to a socket. We chose not to utilize that component above so that we could demonstrate the power of executors and offloading blocking work from the IO thread. See the file server example for how the above program can be implemented in terms of FileRegion.
More examples
We’ve put together a handful of demonstrative servers and clients in the examples directory of the Wangle repository. They include:
- A Telnet server and client — our most basic example
- A file server that, as mentioned above, utilizes a zero-copy async file transfer mechanism to efficiently transfer files
- A proxy server that proxies all traffic to a specified remote address
- An “accept steering” server that demonstrates how to steer client connections to specific IO threads
- An RPC server that demonstrates the most basic of our Finagle-like features (not covered in this post)
Conclusion
Wangle enables the development of highly performant, asynchronous, and modular servers and clients in C++. It has been used to great effect to simplify and, in some cases, increase performance in Facebook open source projects such as fbthrift and Proxygen, in addition to other internal projects. It is production-grade and is considered stable, but we welcome any pull requests on our GitHub page. We hope you find it useful!
Acknowledgements
Wangle was created by Hans Fugal, Blake Matheny, James Sedgwick, and Dave Watson, with contributions from a number of others along the way. Special thanks to all of our contributors, as well as to the authors of Netty and Finagle, in particular Norman Maurer and Marius Eriksen, for providing constant inspiration.


")