
Over the last couple of years, we have built and deployed a reliable publish-subscribe system called Wormhole. Wormhole has become a critical part of Facebook’s software infrastructure. At a high level, Wormhole propagates changes issued in one system to all systems that need to reflect those changes – within and across data centers.
One application of Wormhole is to connect our user databases (UDBs) with other services so they can operate based on the most current data. Here are three examples of systems that receive updates via Wormhole:
- Caches – Refills and invalidation messages need to be sent to each cache so they stay in sync with their local database and consistent with each other.
- Services – Services such as Graph Search that build specialized social indexes need to remain current and receive updates to the underlying data.
- Data warehouse – The Data warehouses and bulk processing systems (Hadoop, Hbase, Hive, Oracle) receive streaming, real-time updates instead of relying on periodic database dumps.
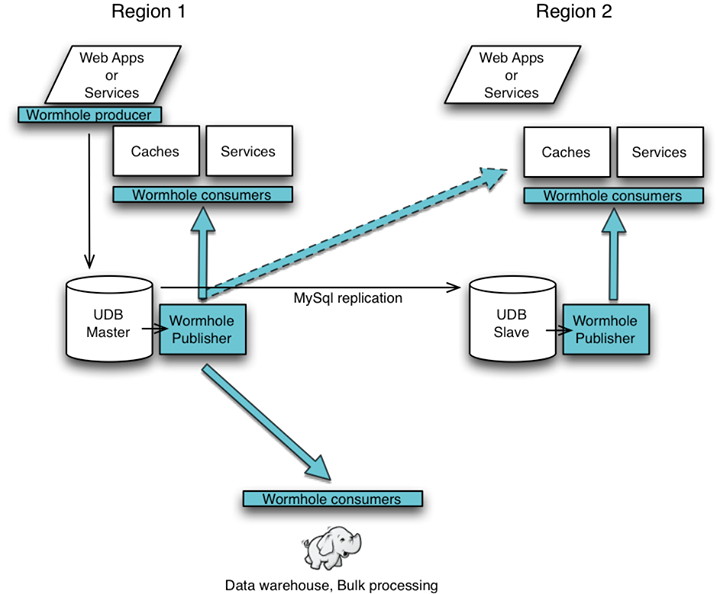
The Wormhole system has three primary components:
- Producer – Services and web tier use the Wormhole producer library to embed messages that get written to the binary log of the UDBs.
- Publisher – The Wormhole publisher tails the binary log, extracts the embedded messages, and makes them available as real-time streams that can be subscribed to.
- Consumer – Each interested consumer subscribes to relevant updates.
In order to satisfy a wide variety of use-cases, Wormhole has the following properties:
- Data partitioning: On the databases, the user data is partitioned, or sharded, across a large number of machines. Updates are ordered within a shard but not necessarily across shards. This partitioning also isolates failures, allowing the rest of the system to keep working even when one or more storage machines have failed. Wormhole maintains a separate publish-subscribe stream per shard–think parallel wormholes in space.
- Rewind in time: To deal with different failures (network, software, and hardware), services need to be able to go back to an earlier data checkpoint and start applying updates from that point onward. Wormhole supports check-pointing, state management, and a rewind feature.
- Reliable in-order delivery: Wormhole provides at-least-once, ordered delivery of data that guarantees that the most recent update with the freshest data is applied last. For example, a prolonged datacenter outage may cause a stream to be backlogged. In addition to the normal ordered delivery, some consumers may want to restore the high priority real-time stream as fast as possible while recovering the backlog in parallel. Consumers can deal with this potential ordering violation using a conflict-resolution mechanism such as versioning.
- Atomicity: Wormhole producers combine Wormhole messages with the database operations themselves in order to guarantee atomicity. If and only if the database operation succeeds, the messages will be found in the binary log and Wormhole publisher will deliver it.
- Low-latency: Wormhole streams the messages asynchronously and minimizes the delay between when the user data is updated in the database and when it is reflected globally. In a globally distributed system like Facebook, it is impractical to send these updates synchronously without sacrificing availability. In practice, thanks to streaming, the Wormhole latency is only a couple of milliseconds more than the network latency.
- Efficiency: Wormhole delivers messages to dozens of services, many with thousands of machines. This requires Wormhole to be highly scalable and very efficient. Wormhole minimizes the load on the data source by multiplexing data stream subscriptions onto significantly smaller sets we call caravans. Wormhole supports comprehensive sampling and server-side filtering, which reduces the amount of data sent. Wormhole publishers can be chained in order to multiplex and route data to reduce network costs over expensive network links.
Thanks to all of these properties, we are able to run Wormhole at a huge scale. For example, on the UDB deployment alone, Wormhole processes over 1 trillion messages every day (significantly more than 10 million messages every second). Like any system at Facebook’s scale, Wormhole is engineered to deal with failure of individual components, integrate with monitoring systems, perform automatic remediation, enable capacity planning, automate provisioning and adapt to sudden changes in usage pattern.
In addition to handling our scale, Wormhole’s two biggest wins for our infrastructure have been greatly improved cache consistency across data centers and real-time loading of transactional data into data warehouses. Compared to the previous system, Wormhole reduced CPU utilization on UDBs by 40% and I/O utilization by 60%, and reduced latency from a day down to a few seconds.
In the near future, Wormhole will evolve to support features like application-specific SLA and QoS. When multiple copies of data are available, Wormhole will optimize for latency, overall cost, and throughput by dynamically choosing and switching data sources based on these parameters. Wormhole will thus enable seamless global failover and enhance disaster recovery readiness for those applications. As we keep scaling support for more messages and new applications, we will continue to develop Wormhole as an efficient, highly-reliable piece of our infrastructure.
Thanks to all the engineers who worked on building Wormhole: David Callies, Evgeniy Makeev, Harry Li, Laurent Demailly, Liat Atsmon Guz, Petchean Ang, Peter Xie, Philippe Ajoux, Sabyasachi Roy, Sachin Kulkarni, Thomas Fersch, Yee Jiun Song, Yogeshwer Sharma.











