
Machine learning drives many aspects of people’s experience on Facebook. We use automatic language translation systems to remove communication barriers and enable people to interact with each other even if they speak different languages. Our image classification systems not only allow people to search for photos of their favorite moments, but also provide an immersive experience for the visually impaired with “talking images” that can be read with your fingertips. We also use machine learning in speech recognition, object and facial recognition, style transfer, video understanding, and many other services across our family of applications.
Given the growing demand of machine learning workloads, Facebook has been dedicated to advancing the state of artificial intelligence and its disciplines through open source contributions and collaboration. Building cutting-edge platforms to support and accelerate the growing demand of AI has been one of our key focuses. Over the past few years, we have been increasing our investments in machine learning hardware in our data centers to focus on accelerating the use of neural networks in our products and services. In 2013, we began our initial deployments with the HP SL270s G8 system for AI research. We learned a great deal about deploying GPUs at scale in our data centers, and identified serviceability, thermal efficiency, performance, reliability, and cluster management to be focus areas for our next generation systems. Subsequently, we contributed two server designs to the Open Compute Project (OCP) — Big Sur, followed by Big Basin — and have added them to our data center fleet.

These hardware platforms have become the backbone of Facebook’s AI research and machine learning services. Today, we are excited to announce our next step of hardware innovation — Big Basin v2.
Introducing Big Basin v2
Built on the same building blocks as the previous Big Basin system, the modular design allows us to leverage and assemble existing Open Compute Project (OCP) components to build our Big Basin v2 system. Due to the added performance of the latest generation NVIDIA Tesla V100 GPU accelerators, we also upgraded the head-node to Tioga Pass for additional CPU performance, and doubled the PCIe bandwidth between the CPUs and GPUs. In addition, we upgraded the OCP network card to provide additional network bandwidth for distributed training workloads. With these upgrades, we not only observed a 66% increase in single-GPU performance compared to our previous generation system, but also achieved a near-linear performance improvement in large-scale distributed GPU training. This empowers our researchers and engineers to build even larger and more complex machine learning models to further improve user experience.





Facebook’s machine learning pipeline
Big Basin v2 is the latest in a series of state-of-the-art hardware and software platforms that support Facebook’s machine learning workflows and have been released through OCP or other open source initiatives.
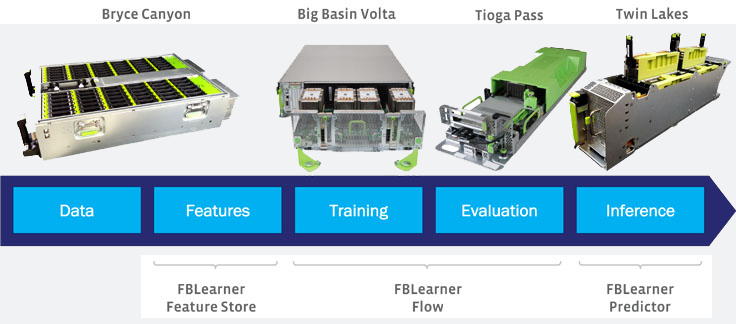
Most of the machine learning pipelines at Facebook run though FBLearner, our AI software platform that includes Feature Store, Flow, and Predictor. Feature Store generates features from the data and feeds them into FBLearner Flow. Flow is used to build, train, and evaluate machine learning models based on the generated features. The final trained models are then deployed to production via FBLearner Predictor. Predictor makes inferences or predictions on live traffic. For example, it predicts which stories, posts, or photos someone might care about most.
The entire FBLearner platform is powered by Facebook’s designed hardware that have been released to OCP. The data storage and Feature Store is supported by Bryce Canyon; FBLearner Flow trains model on the Tioga Pass CPU or Big Basin v2 GPU systems; and FBLearner Predictor utilizes our compute systems Tioga Pass and Twin Lakes.
Future hardware designs
To support the rapidly growing variety and importance of machine learning workloads, Facebook is dedicated to advancing state-of-art AI infrastructure hardware. We are working with our partners to design more energy-efficient systems that are optimized for our training and inference phases, with focuses on performance and power efficiency, intra-node and inter-node communication, which enables large-scale distributed training, and storage efficiency and data locality, for managing increasing amounts data in machine learning pipeline.
We believe that collaborating in the open helps foster innovation for future designs and will allow us to build more complex AI systems that will ultimately power more immersive Facebook experiences.
The design specifications and collateral for Big Basin v2 are publicly available through the OCP Marketplace.











