
Facebook has one of the largest MySQL database clusters in the world. This cluster comprises many thousands of servers across multiple data centers on two continents.
Operating a cluster of this size with a small team is achieved by automating nearly everything a conventional MySQL Database Administrator (DBA) might do so that the cluster can almost run itself. One of the core components of this automation is a system we call MPS, short for “MySQL Pool Scanner.”
MPS is a sophisticated state machine written mostly in Python. It replaces a DBA for many routine tasks and enables us to perform maintenance operations in bulk with little or no human intervention.
A closer look at a single database node
Every one of the thousands of database servers we have can house a certain number of MySQL instances. An instance is a separate MySQL process, listening on a separate port with its own data set. For simplicity, we’ll assume exactly two instances per server in our diagrams and examples.
The entire data set is split into thousands of shards, and every instance holds a group of such shards, each in its own database schema. A Facebook user’s profile is assigned to a shard when the profile is created and every shard holds data relating to thousands of users.
It’s more easily explained by a diagram of a single database server:
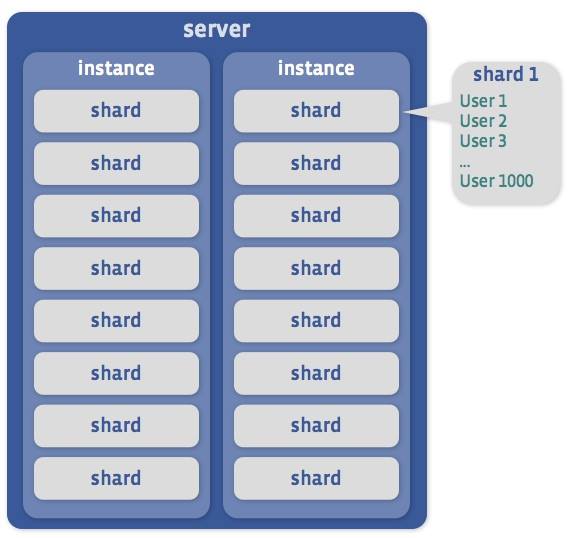
Every instance has a few copies of its data on other instances that are hosted on different servers, and usually in a different data center. This is done to achieve two main goals:
1. High Availability – If a server goes down, we have the data available elsewhere, ready to be served.
2. Performance – Different geographical regions have their own replicas so that reads are served locally.
The way we achieve this is through simple MySQL primary/secondary replication. Every instance is part of a replica set. A replica set has a primary and multiple secondaries. All writes to a replica set must occur on the primary. The secondaries subscribe to a stream of these write events, and the events are replayed on them as soon as they arrive. Since the primary and the secondaries have nearly identical data, a read can occur on any one of the instances in the replica set.
Here is a diagram of a simple replica set, where each server hosts only one instance, and the other instance is empty (we call these spares):
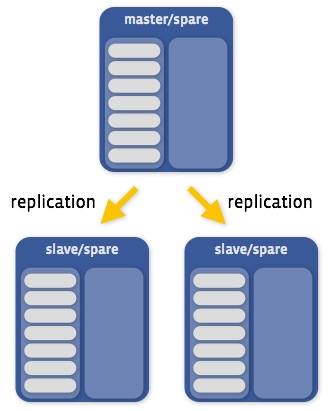
A server is essentially a container for instances, so in reality things can get much more complicated.
For example, a single server hosting a primary instance may also be hosting a secondary instance for a different primary, like so:
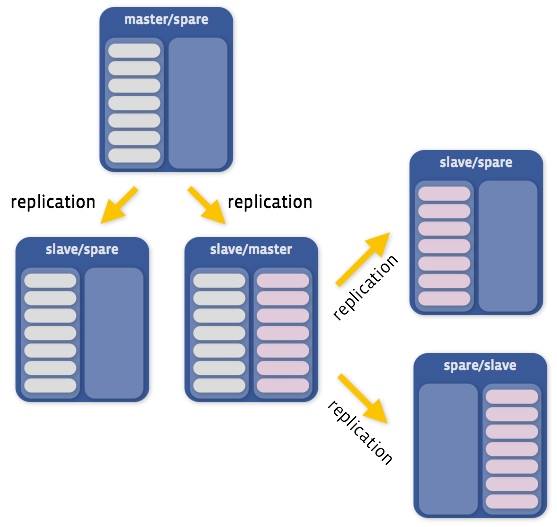
There are two important “building block” operations MPS relies on:
1. Creating a copy/placing a server
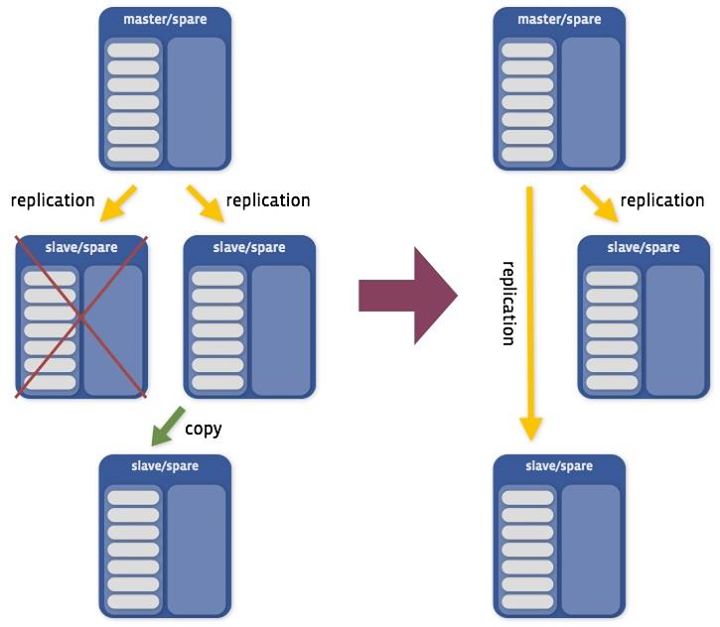
The first building block is an operation that creates a copy of an instance on a different host. We use a modified version of Xtrabackup to perform most copy operations. A replacement is the same operation if we remove an instance after a copy successfully completes.
First, the system allocates a new spare instance for the operation. We choose one of the secondaries or the primary and copy its data to the freshly allocated spare instance. This diagram shows a replacement operation, where an instance is removed when the copy is complete:
2. Promoting a primary instance
The second building block is the action of promoting a different instance to be the primary in a replica set.
During a promotion, we select a target for the promotion, stop writes to the replica set, change the secondaries to replicate from the new primary, and resume writes. In the diagram, we show a deletion operation in which the old primary is discarded after the promotion is completed successfully. For simplicity, the replica set below consists of only three instances:
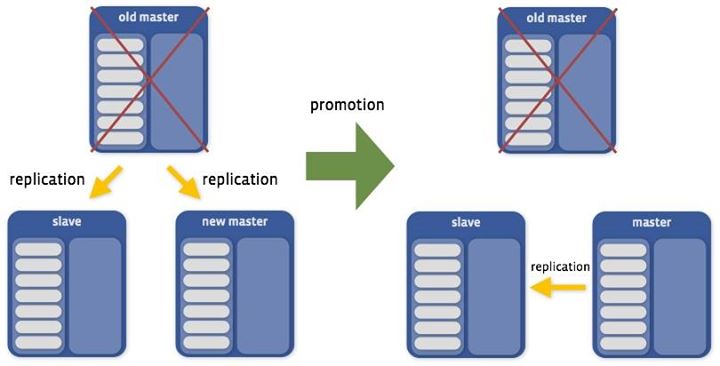
These two operations (which are usually complex procedures for most companies running MySQL) have been completely automated to a point where MPS can run them hundreds or thousands of times a day in a fast and safe manner, without any human intervention.
Host management and states
Now that we’ve got the basics out of the way, we can dive into more abstract concepts that utilize these building blocks.
MPS works with a repository that holds the current state and metadata for all our database hosts, and current and past MPS copy operations. This registry is managed by the database servers themselves so that it scales with the database cluster and MPS doesn’t need a complex application server installation. MPS itself is in fact stateless, running on its own pool of hosts and relying on the repository for state management. States are processed separately and in parallel.
When a server “wakes up” in a datacenter (for example, a fresh rack has been connected and provisioned), it will start running a local agent every few minutes. This agent performs the following steps:
- Collect data about itself. (Where am I? What hardware do I have? What software versions am I running?)
- Triage the host for problems. (Did I wake up in an active cluster? Are my disks OK? Are my flash cards healthy?)
- Make sure the server is registered and contains up-to-date metadata in the central repository.
- On the first run, place instances on the server in an initial “reimage” state if there is no current record of this server. This is where new servers start their lives in MPS.
- So every few minutes, every healthy server “checks in” to this central repository and updates how it’s doing, allowing things like data use and system health to be kept in sync.
The smallest unit MPS manages at the moment is an instance. Each instance can be in various states. The important states are as follows:
- Production: Instance is serving production traffic.
- Spare: Instance is ready to be copied to or allocated to some other task.
- Spare allocated: Instance has been chosen as the target for a copy, and a copy is in progress.
- Spare deallocated: Temporary triaging state. Instance has been removed from production and is pending triaging and cleanup. No instances stay here for more than a few minutes.
- Drained: The instance is not being used, and is being reserved for testing, data center maintenance, etc. An operator intervention is required to take a host out of this state.
- Reimage: Servers with all instances in this state are being reimaged or are in the process of being repaired. Servers in this state are handed off and managed by a co-system called Windex, which was discussed in a previous post.
An instance may move between states due to MPS executing an action or an operator intervention. This state diagram shows the main states and the actions that may cause an instance to move between those states.
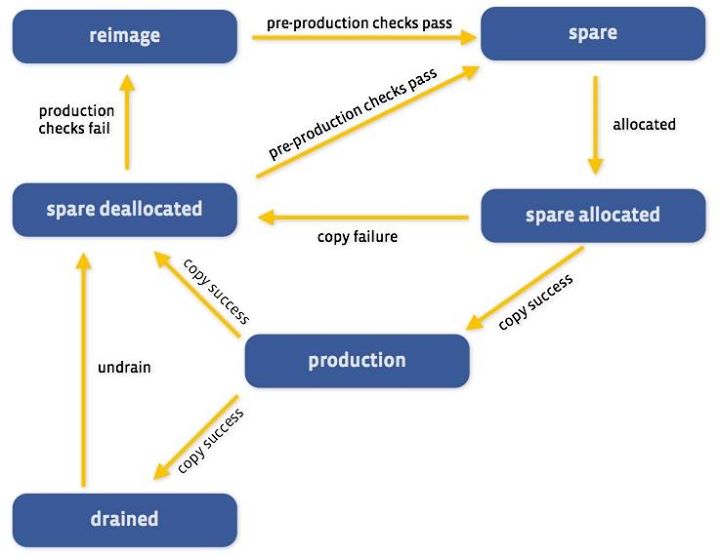
The diagram above describes only a small subset of possible paths an instance may take in MPS. The state changes described here are the ones that result from simple copy and maintenance operations. There are many other reasons for instances to change states, and hardcoding all the options and checks would create software that is difficult and complex to maintain. Meet “problems,” another fundamental concept in MPS.
A “problem” is a property that is attached to an instance. If all instances on a host have this problem, we consider it to be attached to the server itself. Another way to think of problems is like tags. MPS consults a decision matrix that helps it make decisions about instances with a specific problem. It is basically a map between tuples: (state, problem) – (action, state).
It is easier to understand with some examples:
- (production, low-space) – (replace, spare deallocated): Replace an instance in production with limited space, moving it to a different server.
- (spare de-allocated, old-kernel) – (move, reimage): If an instance happened to move through this state, it has no production data on it, so why not reimage it?
- (production, primary-in-fallback-location) – (promote, production): We should promote this primary instance to the correct location, and leave the instance in the production state.
The various states and “problems” in MPS allow us to create a flexible and maintainable infrastructure to manage a server’s life cycle.
Examples of common failure resolution and maintenance operations
In a large data center, there are tens or hundreds of server failures a day. Here are a few examples of common day-to-day failures that MPS takes care of without human intervention:
- Broken secondary instances are detected and disabled until they are replaced in the background.
- Broken primary instances are demoted so that healthy replicas take the place of their fallen brethren and get replaced in the background.
- Instances on servers that might run out of space due to growth are moved to underutilized servers.
With thousands of servers, site-wide maintenance tasks like upgrading to a new kernel, changing partition sizes, or upgrading firmware on controllers become very complex. The same goes for localized operations such as moving some racks or allocating test servers for our engineering teams. Here are some common maintenance operations an operator can ask MPS to perform with a single command:
- Drain any number of database racks for maintenance and take them out of production. Most such operations complete in less than 24 hours.
- Re-image thousands of machines (to perform kernel upgrades, for example) at a specified concurrency. MPS will replace each machine and then send it to Windex.
- Allocate any number of spares to be used for a new project or testing. Want 200 servers to run tests? No problem.
- Create a copy of the entire Facebook data set at a new data center at a specified concurrency–building out our new Lulea data center, for example!
Automating away the mundane tasks with MPS allow us to better scale the number of servers we manage, and frees up the MySQL Operations team to work on more exciting challenges.
Shlomo Priymak is a MySQL database engineer on the MySQL operations team.











