As more and more computers, smartphones, and other devices come online, transitioning to IPv6 is critical to ensuring the future scalability of the Internet. The world is currently operating on IPv4, but we have run out of IP addresses. IPv6, the next version of this protocol, contains significantly more addresses and will allow the Internet to grow indefinitely. As Computer History Museum docent Dick Guertin put it, we could assign an IPv6 address to every atom on the surface of the earth, and still have enough addresses left to do another 100+ earths.
In preparation for World IPv6 Launch, Facebook participated in the World IPv6 Day test run last year with several other major web companies like Google and Yahoo. Building support for World IPv6 day helped us figure out where we needed to dedicate more work to ensure our IPv6 infrastructure met or exceeded the quality of its IPv4 counterpart. This new infrastructure needed to be just as automated, stable, standardized, and scalable. It also needed to support as many endpoints as possible, including www, mobile, API (Android/iPhone apps), and photo and video uploads. But to understand what went into getting our clusters ready for IPv6, we first need to look at how our clusters work in the IPv4 world.
Layer 3 DSR
Our cluster infrastructure is, as you might guess, somewhat unique. As with most big web shops, we utilize DSR to reduce the number of load balancers we need. However, as our clusters have grown, we’ve moved beyond clusters that exist in a single Layer 2 (L2) domain. In fact, every rack in our clusters has its own L2 domain with its own unique CIDR space and routes to every other rack. Ditching large L2 networks alleviates a lot of pain, and using routing protocols provides an extraordinary level of flexibility.
As part of moving to Layer 3 (L3) clusters, we also had to move to Layer 3 DSR. And if you haven’t heard of L3 DSR, you’re not alone; it’s not widely deployed yet. As with anything in technology, there’s more than one way to skin a cat, so we evaluated all options. The two common methods involve using DSCP bits to pass information about VIPs or using IP-in-IP tunneling. We found that IP-in-IP tunneling was a better fit for us. That may sound odd, but it maps quite well to L2 DSR.
In an L2 network, DSR takes advantage of the fact that only the L2 headers are technically needed to get a packet from the load balancer to the backend host, which allows us to leave the L3 headers untouched. The goal is that after all the layers necessary for delivery are removed, we still have a packet that will cause an IP stack to naturally respond to the client directly (and use a source address of the VIP). So to replicate that in an L3 network, we need L3 headers to get the packet to our backend, and when we remove those, we still need to have IP headers that will make our stack respond to the client from the VIP address. That sounds like two sets of IP headers, and that’s precisely what we have. It looks like this:
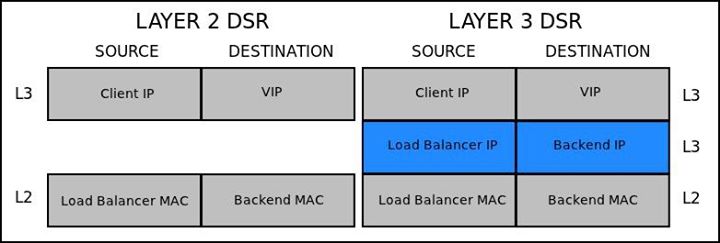
Our hardware load balancers wrap incoming IP packets in an additional L3 packet with a source of the load balancer and destination of the backend. When the backend gets the packet, instead of the VIP being on the loopback (lo) or dummy (dummy0) interfaces, we put it on a tunnel (tunl0) interface. The tunl driver decapsulates the packet and then accepts the internal packet, which has a source of the client and a destination of the VIP (which was our goal).
IP6-in-IP6 tunneling
We wanted to replicate the set up above for IPv6, and we wanted full IPv6 to our backends (or at least the first level of them). This meant those backends needed their own IPv6 addresses… but so did the load balancers and all the routers inside the cluster. And that meant our internal software which configures these devices also needed to understand IPv6. And that meant our network tools which allocate networks to routers and addresses to hosts needed to support IPv6. And all of that is before we even get to the Facebook application code.
We worked with our load balancer vendor to implement IP6-in-IP6 tunneling. Then we got the VIPs up on an ip6tnl0 interface. And then…it didn’t work. As it turns out, the Linux IPv4 tunnel driver will – on the “fallback device” (tunl0) – decapsulate IP-in-IP packets by default, but the IPv6 tunnel driver will only decapsulate packets that match an explicit tunnel that’s been added (as opposed to an address on the fallback device, ip6tnl0). So we wrote a quick-n-dirty patch to emulate the v4 driver’s behavior, and it worked! IPv6 packets that hit our frontend load balancers are now encapsulated in another set of IPv6 headers, sent to the backend, decapsulated and accepted. These backends make requests to other parts of Facebook over IPv4 in order to service the request, as most backend services are not yet using IPv6. However, when you make an IPv6 connection to Facebook – whether reading your newsfeed, uploading a photo, or using the Android or iPhone app – you’re speaking IPv6 all the way to the server that terminates your connection. IPv6 is now a first-class citizen in our infrastructure: no new endpoints or clusters are turned up without it.
The aforementioned kernel patch wasn’t safe for general consumption, but we’ve already engaged the kernel community to find a generic solution which has been sent upstream.
I was but one of many people who made this transition to IPv6 possible. It would not have happened without the hard work of Paul Saab, Jimmy Williams, Donn Lee, Alan Wang, Alex Renzin, Joel Dodge, Phil Liu, Matt Jones, Scott Renfro, Bill Fumerola, John Allen, Callahan Warlick, Dan Rampton, J Crawford, and many more. Solving IPv6 Layer 3-based DSR is just one example of the many cool problems we get to tackle every day at Facebook, and there’s still much more for our team to do to bring IPv6 to other parts of our infrastructure.


")