
People are creating, sharing, and storing data at a faster rate than at any other time in history. When it comes to innovating on storing and transmitting that data, at Facebook we're making advancements not only in hardware — such as larger hard drives and faster networking equipment — but in software as well. Software helps with data processing through compression, which encodes information, like text, pictures, and other forms of digital data, using fewer bits than the original. These smaller files take up less space on hard drives and are transmitted faster to other systems. There's a trade-off to compressing and decompressing information, though: time. The more time spent compressing to a smaller file, the slower the data is to process.
Today, the reigning data compression standard is Deflate, the core algorithm inside Zip, gzip, and zlib [2]. For two decades, it has provided an impressive balance between speed and space, and, as a result, it is used in almost every modern electronic device (and, not coincidentally, used to transmit every byte of the very blog post you are reading). Over the years, other algorithms have offered either better compression or faster compression, but rarely both. We believe we've changed this.
We're thrilled to announce Zstandard 1.0, a new compression algorithm and implementation designed to scale with modern hardware and compress smaller and faster. Zstandard combines recent compression breakthroughs, like Finite State Entropy, with a performance-first design — and then optimizes the implementation for the unique properties of modern CPUs. As a result, it improves upon the trade-offs made by other compression algorithms and has a wide range of applicability with very high decompression speed. Zstandard, available now under the BSD license, is designed to be used in nearly every lossless compression [1] scenario, including many where current algorithms aren't applicable.
Comparing compression
There are three standard metrics for comparing compression algorithms and implementations:
- Compression ratio: The original size (numerator) compared with the compressed size (denominator), measured in unitless data as a size ratio of 1.0 or greater.
- Compression speed: How quickly we can make the data smaller, measured in MB/s of input data consumed.
- Decompression speed: How quickly we can reconstruct the original data from the compressed data, measured in MB/s for the rate at which data is produced from compressed data.
The type of data being compressed can affect these metrics, so many algorithms are tuned for specific types of data, such as English text, genetic sequences, or rasterized images. However, Zstandard, like zlib, is meant for general-purpose compression for a variety of data types. To represent the algorithms that Zstandard is expected to work on, in this post we'll use the Silesia corpus, a data set of files that represent the typical data types used every day.
Some algorithms and implementations commonly used today are zlib, lz4, and xz. Each of these algorithms offers different trade-offs: lz4 aims for speed, xz aims for higher compression ratios, and zlib aims for a good balance of speed and size. The table below indicates the rough trade-offs of the algorithms' default compression ratio and speed for the Silesia corpus by comparing the algorithms per lzbench, a pure in-memory benchmark meant to model raw algorithm performance.
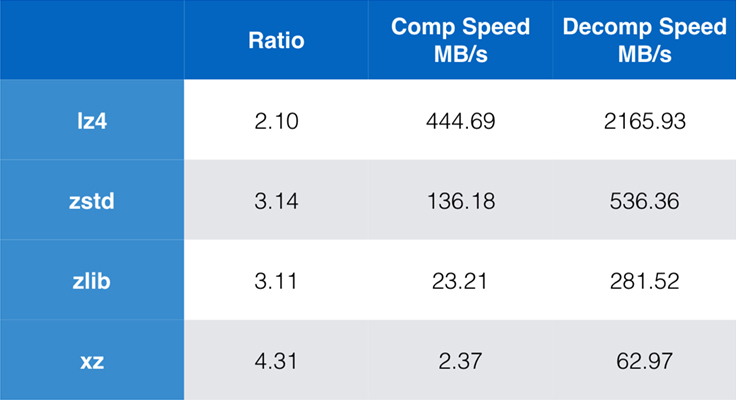
As outlined, there are often drastic compromises between speed and size. The fastest algorithm, lz4, results in lower compression ratios; xz, which has the highest compression ratio, suffers from a slow compression speed. However, Zstandard, at the default setting, shows substantial improvements in both compression speed and decompression speed, while compressing at the same ratio as zlib.
While pure algorithm performance is important when compression is embedded within a larger application, it is extremely common to also use command line tools for compression — say, for compressing log files, tarballs, or other similar data meant for storage or transfer. In these cases, performance is often affected by overhead, such as checksumming. This chart shows the comparison of the gzip and zstd command line tools on Centos 7 built with the system's default compiler.
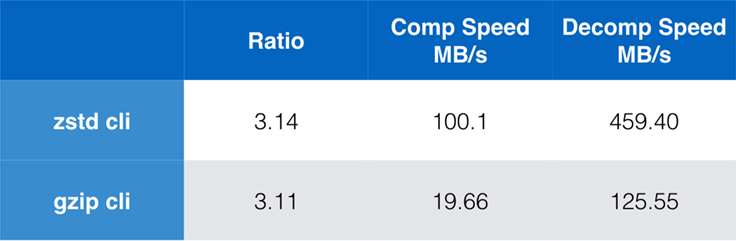
The tests were each conducted 10 times, with the minimum times taken, and were conducted on ramdisk to avoid filesystem overhead. These were the commands (which use the default compression levels for both tools):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 bytes
zstd -d -c silesia.tar.zst > /dev/null
gzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytes
gzip -d -c silesia.tar.gz > /dev/null
Scalability
If an algorithm is scalable, it has the ability to adapt to a wide variety of requirements, and Zstandard is designed to excel in today's landscape and to scale into the future. Most algorithms have "levels” based on time/space trade-offs: The higher the level, the greater the compression achieved at a loss of compression speed. Zlib offers nine compression levels; Zstandard currently offers 22, which enables flexible, granular trade-offs between compression speed and ratios for future data. For example, we can use level 1 if speed is most important and level 22 if size is most important.
Below is a chart of the compression speed and ratio achieved for all levels of Zstandard and zlib. The x-axis is a decreasing logarithmic scale in megabytes per second; the y-axis is the compression ratio achieved. To compare the algorithms, you can pick a speed to see the various ratios the algorithms achieve at that speed. Likewise, you can pick a ratio and see how fast the algorithms are when they achieve that level.
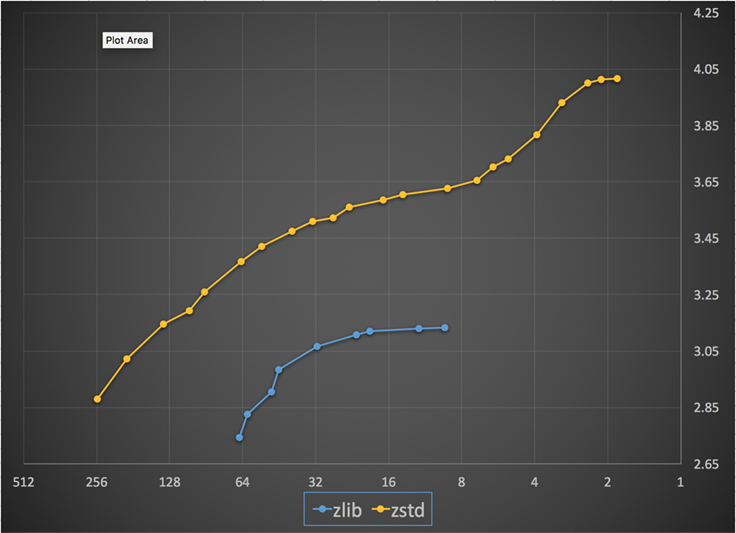
For any vertical line (i.e., compression speed), Zstandard achieves a higher compression ratio. For the Silesia corpus, decompression speed — regardless of ratio — was approximately 550 MB/s for Zstandard and 270 MB/s for zlib. The chart shows another difference between Zstandard and the alternatives: By using one algorithm and implementation, Zstandard allows for much finer-grained tuning for each use case. This means Zstandard can compete with some of the fastest and highest compression algorithms while maintaining a substantial decompression speed advantage. These improvements translate directly to faster data transfer and smaller storage requirements.
In other words, compared with zlib, Zstandard scales:
- At the same compression ratio, it compresses substantially faster: ~3-5x.
- At the same compression speed, it is substantially smaller: 10-15 percent smaller.
- It is almost 2x faster at decompression, regardless of compression ratio; the command line tooling numbers show an even bigger difference: more than 3x faster.
- It scales to much higher compression ratios, while sustaining lightning-fast decompression speeds.
Under the hood
Zstandard improves upon zlib by combining several recent innovations and targeting modern hardware:
Memory
By design, zlib is limited to a 32 KB window, which was a sensible choice in the early '90s. But, today's computing environment can access much more memory — even in mobile and embedded environments.
Zstandard has no inherent limit and can address terabytes of memory (although it rarely does). For example, the lower of the 22 levels use 1 MB or less. For compatibility with a broad range of receiving systems, where memory may be limited, it is recommended to limit memory usage to 8 MB. This is a tuning recommendation, though, not a compression format limitation.
A format designed for parallel execution
Today's CPUs are very powerful and can issue several instructions per cycle, thanks to multiple ALUs (arithmetic logic units) and increasingly advanced out-of-order execution design.
In essence, it means that if:
a = b1 + b2
c = d1 + d2
then both a and c will be calculated in parallel.
This is possible only if there is no relation between them. Therefore, in this example:
a = b1 + b2
c = d1 + a
c must wait for a to be calculated first, and only then will c calculation start.
It means that, to take advantage of the modern CPU, one has to design a flow of operations with few or no data dependencies.
This is achieved with Zstandard by separating data into multiple parallel streams. A new generation Huffman decoder, Huff0, is able to decode multiple symbols in parallel with a single core. Such gain is cumulative with multi-threading, which uses multiple cores.
Branchless design
New CPUs are more powerful and reach very high frequencies, but this is only possible thanks to a multi-stage approach, where an instruction is split into a pipeline of multiple steps. At each clock cycle, the CPU is able to issue the result of multiple operations, depending on available ALUs. The more ALUs that are being used, the more work the CPU is doing, and hence the faster compression is occurring. Keeping the ALUs fed with work is crucial for modern CPU performance.
This turns out to be difficult. Consider the following simple situation:
if (condition) doSomething() else doSomethingElse()When it encounters this, the CPU does not know what to do, since it depends on the value of condition. A cautious CPU would wait for the result of condition before working on either branch, which would be extremely wasteful.
Today's CPUs gamble. They do so intelligently, thanks to a branch predictor, which tells them in essence the most probable result of evaluating condition. When the bet is right, the pipeline remains full and instructions are issued continuously. When the bet is wrong (a misprediction), the CPU has to stop all operations started speculatively, come back to the branch, and take the other direction. This is called a pipeline flush, and is extremely costly in modern CPUs.
Twenty-five years ago, pipeline flush was a non-issue. Today, it is so important that it's essential to design formats compatible with branchless algorithms. As an example, let's look at a bit-stream update:
/* classic version */
while (nbBitsUsed >= 8) { /* each while test is a branch */
accumulator <<= 8;
accumulator += *byte++;
nbBitsUsed -= 8;
}
/*>/* branch-less version */
nbBytesUsed = nbBitsUsed >> 3;
nbBitsUsed &= 7;
ptr += nbBytesUsed;
accumulator = read64(ptr);
As you can see, the branchless version has a predictable workload, without any condition. The CPU will always do the same work, and that work is never thrown away due to a misprediction. In contrast, the classic version does less work when (nbBitsUsed < 8). But the test itself is not free, and whenever the test is guessed incorrectly, it results in a full pipeline flush, which costs more than the work done by the branchless version.
As you can guess, this side effect has impacts on the way data is packed, read, and decoded. Zstandard has been created to be friendly to branchless algorithms, especially within critical loops.
Finite State Entropy: A next-generation probability compressor
In compression, data is first transformed into a set of symbols (the modeling stage), and then these symbols are encoded using a minimum number of bits. This second stage is called the entropy stage, in memory of Claude Shannon, which accurately calculates the compression limit of a set of symbols with given probabilities (called the “Shannon limit”). The goal is to get close to this limit while using as few CPU resources as possible.
A very common algorithm is Huffman coding, in use within Deflate. It gives the best possible prefix code, assuming each symbol is described with a natural number of bits (1 bit, 2 bits …). This works great in practice, but the limit of natural numbers means it's impossible to reach high compression ratios, because a symbol necessarily consumes at least 1 bit.
A better method is called arithmetic coding, which can come arbitrarily close to Shannon limit -log2(P), hence consuming fractional bits per symbol. It translates into a better compression ratio when probabilities are high, but it also uses more CPU power. In practice, even optimized arithmetic coders struggle for speed, especially on the decompression side, which requires divisions with a predictable result (e.g., not a floating point) and which proves to be slow.
Finite State Entropy is based on a new theory called ANS (Asymmetric Numeral System) by Jarek Duda. Finite State Entropy is a variant that precomputes many coding steps into tables, resulting in an entropy codec as precise as arithmetic coding, using only additions, table lookups, and shifts, which is about the same level of complexity as Huffman. It also reduces latency to access the next symbol, as it is immediately accessible from the state value, while Huffman requires a prior bit-stream decoding operation. Explaining how it works is outside the scope of this post, but if you're interested, there is a series of articles detailing its inner working.
Repcode modeling
Repcode modeling efficiently compresses structured data, which features sequences of almost equivalent content, differing by just one or a few bytes. This method isn't new but was first used after Deflate's publication, so it doesn't exist within zlib/gzip.
The efficiency of repcode modeling highly depends on the type of data being compressed, ranging anywhere from a single to a double-digit compression improvement. These combined improvements add up to a better and faster compression experience, offered within the Zstandard library.
Zstandard in practice
As mentioned before, there are several typical use cases of compression. For an algorithm to be compelling, it either needs to be extraordinarily good at one specific use case, such as compressing human readable text, or very good at many diverse use cases. Zstandard takes the latter approach. One way to think about use cases is how many times a specific piece of data might be decompressed. Zstandard has advantages in all of these cases.
Many times. For data processed many times, decompression speed and the ability to opt into a very high compression ratio without compromising decompression speed is advantageous. The storage of the social graph on Facebook, for instance, is repeatedly read as you and your friends interact with the site. Outside of Facebook, examples of when data needs to be decompressed many times include files downloaded from a server, such as the source code to the Linux kernel or the RPMs installed on servers, the JavaScript and CSS used by a webpage, or running thousands of MapReduces over data in a data warehouse.
Just once. For data compressed just once, especially for transmission over a network, compression is a fleeting moment in the flow of data. The less overhead it has on the server means the server can handle more requests per second. The less overhead on the client means the data can be acted upon more quickly. Typically this comes up with client/server situations where the data is unique for the client, such as a web server response that is custom — say, the data used to render when you receive a note from a friend on Messenger. The net result is your mobile device loads pages faster, uses less battery, and consumes less of your data plan. Zstandard in particular suits the mobile scenarios much better than other algorithms because of how it handles small data.
Possibly never. While seemingly counterintuitive, it is often the case that a piece of data — such as backups or log files — will never be decompressed but can be read if needed. For this type of data, compression typically needs to be fast, make the data small (with a time/space trade-off suitable for the situation), and perhaps store a checksum, but otherwise be invisible. On the rare occasion it does need to be decompressed, you don't want the compression to slow down the operational use case. Fast decompression is beneficial because it is often a small part of the data (such as a specific file in the backup or message in a log file) that needs to be found quickly.
In all of these cases, Zstandard brings the ability to compress and decompress many times faster than gzip, with the resulting compressed data being smaller.
Small data
There is another use case for compression that gets less attention but can be quite important: small data. These are use patterns where data is produced and consumed in small quantities, such as JSON messages between a web server and browser (typically hundreds of bytes) or pages of data in a database (a few kilobytes).
Databases provide an interesting use case. Systems such as MySQL, PostgreSQL, and MongoDB all store data intended for real-time access. Recent hardware advantages, particularly around the proliferation of flash (SSD) devices, have fundamentally changed the balance between size and throughput — we now live in a world where IOPs (IO operations per second) are quite high, but the capacity of our storage devices is lower than it was when hard drives ruled the data center.
In addition, flash has an interesting property regarding write endurance — after thousands of writes to the same section of the device, that section can no longer accept writes, often leading to the device being removed from service. Therefore it is natural to seek out ways to reduce the quantity of data being written because it can mean more data per server and burning out the device at a slower rate. Data compression is a strategy for this, and databases also are often optimized for performance, meaning read and write performance are equally important.
There is a complication for using data compression with databases, though. Databases like to randomly access data, whereas most typical use cases for compression read an entire file in linear order. This is a problem because data compression essentially works by predicting the future based on the past — the algorithms look at your data sequentially and predict what it might see in the future. The more accurate the predictions, the smaller it can make the data.
When you are compressing small data, such as pages in a database or tiny JSON documents being sent to your mobile device, there simply isn't much “past” to use to predict the future. Compression algorithms have attempted to address this by using pre-shared dictionaries to effectively jump-start. This is done by pre-sharing a static set of "past" data as a seed for the compression.
Zstandard builds on this approach with highly optimized algorithms and APIs for dictionary compression. In addition, Zstandard includes tooling (zstd --train) for easily making dictionaries for custom applications and provisions for registering standard dictionaries for sharing with larger communities. While compression varies based on the data samples, small data compression can range anywhere from 2x to 5x better than compression without dictionaries.
Dictionaries in action
While it can be hard to play with a dictionary in the context of a running database (it requires significant modifications to the database, after all), you can see dictionaries in action with other types of small data. JSON, the lingua franca of small data in the modern world, tends to be small, repetitive records. There are countless public data sets available; for the purpose of this demonstration, we will use the “user” data set from GitHub, available via HTTP. Here is a sample entry from this data set:
{
"login": "octocat",
"id": 1,
"avatar_url": "https://github.com/images/error/octocat_happy.gif",
"gravatar_id": "",
"url": "https://api.github.com/users/octocat",
"html_url": "https://github.com/octocat",
"followers_url": "https://api.github.com/users/octocat/followers",
"following_url": "https://api.github.com/users/octocat/following{/other_user}",
"gists_url": "https://api.github.com/users/octocat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/octocat/subscriptions",
"organizations_url": "https://api.github.com/users/octocat/orgs",
"repos_url": "https://api.github.com/users/octocat/repos",
"events_url": "https://api.github.com/users/octocat/events{/privacy}",
"received_events_url": "https://api.github.com/users/octocat/received_events",
"type": "User",
"site_admin": false
}
As you can see, there is quite a bit of repetition here — we can compress these nicely! But each user is a bit under 1 KB, and most compression algorithms really need more data to stretch their legs. A set of 1,000 users takes roughly 850 KB to store uncompressed. Naively applying either gzip or zstd individually to each file cuts this down to just over 300 KB; not bad! But if we create a one-time, pre-shared dictionary, with zstd the size drops to 122 KB — taking the original compression ratio from 2.8x to 6.9. This is a significant improvement, available out-of-box with zstd:
$ zstd --train -o ../json.zdict -r .
sorting 982 files of total size 0 MB ...
finding patterns ...
statistics ...
Save dictionary of size 65599 into file ../json.zdict
$ du -h --apparent-size .
846K .
$ zstd --rm -D ../json.zdict -r .
$ du -h --apparent-size .
122K .
Picking a compression level
As shown above, Zstandard provides a substantial number of levels. This customization is powerful but leads to tough choices. The best way to decide is to review your data and measure, deciding what trade-offs you want to make. At Facebook, we find the default level 3 suitable for many use cases, but from time to time, we will adjust this slightly depending upon what our bottleneck is (often we are trying to saturate a network connection or disk spindle); other times, we care more about the stored size and will use a higher level.
Ultimately, for the results most tailored to your needs, you will need to consider both the hardware you use and the data you care about — there are no hard and fast prescriptions that can be made without context. When in doubt, though, either stick with the default level of 3 or something from the 6 to 9 range for a nice trade-off of speed versus space; save level 20+ for cases where you truly care only about the size and not about the compression speed.
Try it out
Zstandard is both a command line tool (zstd) and a library. It is written in highly portable C, making it suitable for practically every platform used today — be it the servers that run your business, your laptop, or even the phone in your pocket. You can grab it from our github repository, compile it with a simple make install, and begin using it like you would use gzip:
$ zstd access.log
access.log : 8.07% (6695078 => 540336 bytes, access.log.zst)
As you might expect, you can use it as part of a command pipeline, for example, to back up your critical MySQL database:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zst
The tar command supports different compression implementations out-of-box, so once you install Zstandard, you can immediately work with tarballs compressed with Zstandard. Here's a simple example that shows it in use with tar and the speed difference compared with gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4
tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4
3.15s user 0.50s system 107% cpu 3.396 total
$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4
tar -zcf linux-4.6.4.tar.gz linux-4.6.4
13.74s user 0.43s system 102% cpu 13.784 total
Beyond command line use, there are the APIs, documented in the header files in the repository (start here for an overview of the APIs). We also include a zlib-compatible wrapper API (libWrapper) for easier integration with tools that already have zlib interfaces. Finally, we include a number of examples, both of basic use and of more advanced use such as dictionaries and streaming, also in the GitHub repository.
More to come
While we have hit 1.0 and consider Zstandard ready for every kind of production use, we're not done. Coming in future versions:
- Multi-threaded command line compression for even faster throughput on large data sets, similar to the pigz tool for zlib.
- New compression levels, in both directions, allowing for even faster compression and higher ratios.
- A community-maintained predefined set of compression dictionaries for common data sets such as JSON, HTML, and common network protocols.
We would like to thank all contributors, both of code and of feedback, who helped us get to 1.0. This is just the beginning. We know that for Zstandard to live up to its potential, we need your help. As mentioned above, you can try Zstandard today by grabbing the source or pre-built binaries from our GitHub project, or, for Mac users, installing via homebrew (brew install zstd). We'd love any feedback and interesting use cases you have, as well as additional language bindings and help integrating it with your favorite open source projects.
Footnotes
- While lossless data compression is the focus of this post, there exists a related but very different field of lossy data compression, used primarily for images, audio, and video.
- Deflate, zlib, gzip — three names intertwined. Deflate is the algorithm used by the zlib and gzip implementations. Zlib is a library providing Deflate, and gzip is a command line tool that uses zlib for Deflating data as well as checksumming. This checksumming can have significant overhead.
- All benchmarks were performed on an Intel E5-2678 v3 running at 2.5 GHz on a Centos 7 machine. Command line tools (
zstdandgzip) were built with the system GCC, 4.8.5. Algorithm benchmarks performed by lzbench were built with GCC 6.











