
Humans learn by observing and experiencing the physical world. We can imagine a not-too-distant future where a complete artificial intelligence system is capable of not only text and image recognition but also higher-order functions like reasoning, prediction, and planning, rivaling the way humans think and behave. For machines to have this type of common sense, they need an internal model of how the world works, which requires the ability to predict. What we're missing is the ability for a machine to build such a model itself without requiring a huge amount of effort by humans to train it.
Our brains are very good at prediction — for example, knowing that a pen will fall to the floor if you drop it or where to put your hand to catch a ball without having to do explicit computations to arrive at the correct answer. Adversarial networks have recently surfaced as a new way to train machines to predict what's going to happen in the world simply by observing it. An adversarial network has a generator, which produces some type of data — say, an image — from some random input, and a discriminator, which gets input either from the generator or from a real data set and has to distinguish between the two — telling the real apart from the fake. The two neural networks optimize themselves, resulting in more realistic generations and the networks having a better sense of what is plausible in the real world. Adversarial training was originally proposed by Ian Goodfellow and his colleagues at the University of Montreal.
However, generative adversarial networks (GANs) were previously thought to be unstable. Sometimes the generator never started learning or producing what we would perceive to be good generations. At Facebook AI Research (FAIR), we've published a set of papers on stabilizing adversarial networks in collaboration with our partners, starting with image generators using Laplacian Adversarial Networks (LAPGAN) and Deep Convolutional Generative Adversarial Networks (DCGAN), and continuing into the more complex endeavor of video generation using Adversarial Gradient Difference Loss Predictors (AGDL). Regardless of what kinds of images or videos we gave to these systems, they would start learning and predict plausible scenarios of the world.
Deep learning and convolutional neural nets
In computer vision, convolutional neural networks (CNNs) have been successful at training on supervised data sets for image recognition, but unsupervised representational learning has not progressed as far. One of the reasons is that we don't know what happens inside the “black box,” and we want to understand the purpose of each algorithm.
With deep learning, we can train layers of the system individually and develop a hierarchy of layers with more complex understanding, from edges of objects to full objects to scenes. Deep learning methods can also be applied to image generation. Instead of having a neural network that takes an image and tells you whether it's a dog or an airplane, it does the reverse: It takes a bunch of numbers that describe the content and then generates an image accordingly.
Adversarial training is complicated because we have to optimize for both an image generator and a discriminator at the same time. This is like finding a mountain pass; one point is simultaneously the lowest height between two peaks and the highest point between two valleys. This type of optimization is difficult, and if the model weren't stable, we would not find this center point.
While previous attempts to use CNNs to train generative adversarial networks were unsuccessful, when we modified their architecture to create DCGANs, we were able to visualize the filters the networks learned at each layer, thus opening up the black box.
The properties of adversarial networks
In simple terms, in an adversarial network the output of the discriminator is a one for a real image and a zero for a generated image. The discriminator wants to be good at this, so it optimizes itself to not be fooled by the generator. In turn, the generator is optimizing itself to fool the discriminator as much as possible, so it wants to produce images that are so realistic that the discriminator can't tell the difference. Eventually, the generator starts producing such realistic images that the discriminator has a constant probability of being correct half the time, regardless of whether it's a generated image or a real one.
This adversarial training procedure differs from traditional neural networks in an important way. A neural network needs to be given a cost function — a function that evaluates how well the network is doing. This cost function forms the basis of what the neural network learns and how well it learns. A traditional neural network is given a cost function that is carefully constructed by a human scientist. For complex processes such as generative models, constructing a good cost function is not a trivial task. This is where the adversarial network shines. The adversarial network learns its own cost function — its own complex rules of what is correct and what is wrong — bypassing the need to carefully design and construct one.
Practically, this property of adversarial networks translates to better, sharper generations and higher-quality predictive models. To showcase this, LAPGANs and DCGANs have been trained on a wide variety of image data sets capturing either a specific set of images such as faces, paintings, and bedrooms, or a set of diverse natural images in the ImageNet data set. DCGANs in particular have become quite popular in the AI community, and several researchers have taken the code that we released for DCGANs and trained new DCGANs on various sets of images. For example, here's a DCGAN trained by researchers from NVIDIA on 18th-century paintings.

We saw that DCGANs trained on large data sets can learn a hierarchy of features without any supervision. When we used the trained discriminators for image classification tasks on other data sets, DCGANs performed as well as or better than other unsupervised training models. We were also able to visualize the filters that DCGANs learned at each layer, and to empirically show that it learned how to draw specific objects based on the representations it learned. In the bedroom image set, for example, when we removed the representation for “windows” from the generator input, the network mostly replaced windows with other objects, like doors or TVs, suggesting that it was able to disentangle scene representation from object representation.
DCGANs are also able to identify patterns and put similar representations together in some dimension space. In the faces data set, for example, the generator doesn't understand what smiling means, but it finds similarities in images of smiling people and groups them together. Building on similar work that has been done with text, we investigated whether simple arithmetic reveals rich relationships in this space. We found that averaging three exemplars produced consistent and stable generations that semantically obeyed the arithmetic.

This demonstration of unsupervised generative models learning object attributes like scale, rotation, position, and semantics was one of the first.
Smarter machines
Once we train a machine to predict what the world is going to look like, we can apply what it learns to different tasks. If we take two images, one with the camera moved slightly to the left for a different viewpoint, the machine will observe the differences and learn that the world is three-dimensional. Then, it could apply that knowledge to a new scenario, such as knowing how far someone would need to reach to grab a pen from across the table. As machines acquire this common sense, they become better at knowing the best approach to do some particular task, and can quickly reject any hypotheses that would be implausible in the real world, such as trying to walk through a door without opening it first. Ultimately, this type of knowledge could help further accelerate the development of applications including advanced chat bots and virtual assistants.
In our AGDL work, we progress toward this goal of predicting what will happen. We take a few frames of video and build models that predict what comes next. For a game of billiards, for example, that means predicting the next few frames of the balls moving, as soon as the shot is hit.
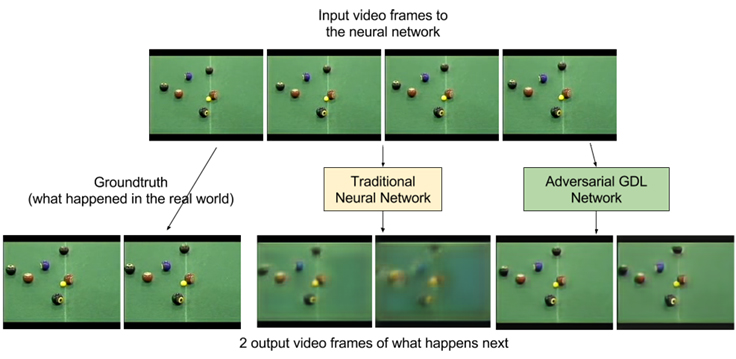
While ADGLs have been a significant first step in forward video prediction, we see the need for a healthy set of improvements to our current models, so that they can predict farther into the future, before we can start reasoning over the predictions of these models and using them to plan. Adversarial networks provide a strong algorithmic framework for building unsupervised learning models that incorporate properties such as common sense, and we believe that continuing to explore and push in this direction gives us a reasonable chance of succeeding in our quest to build smarter AI.











