
As we’re building and running systems at Facebook, sometimes we encounter metastable failure states. These are problems that create conditions that prevent their own solutions. In gridlocked traffic, for example, cars that are blocking an intersection keep traffic from moving, but they can’t exit the intersection because they are stuck in traffic. This kind of failure ends only when there is an external intervention like a reduction in load or a complete reboot.
This blog post is about code that caused a tricky metastable failure state in Facebook’s systems, one that defied explanation for more than two years. It is a great example of interesting things that happen only at scale, and how an open and cooperative engineering culture helps us solve hard problems.
Aggregated Links
Some packets inside a data center traverse several switches to get from one server to another. The switch-to-switch connections on these paths carry a lot of traffic, so these links are aggregated.
An aggregated link uses multiple network cables to carry traffic between the same source and destination. Each packet goes over only one cable, so the switches need a strategy for routing the packets. For TCP traffic, Facebook configures the switches to select the link based on a hash of source IP, source port, destination IP, and destination port. This keeps all the packets of a TCP stream on the same link, avoiding out-of-order delivery. There are lots of streams, so this routing scheme evenly balances the traffic between the links.
Except when it doesn’t.
The reality is that sometimes most of the active TCP connections would be hashed to a single link. That link would be overloaded and drop packets. Even worse, this failure state was metastable. Once an imbalanced link became overloaded, the rest of the links would remain uselessly idle until traffic was drained or the hash algorithm was changed.
For two years, we tackled this problem at the switch level. We worked with our vendors to detect imbalance and rapidly rotate the hash function’s seed when it occurred. This kept the problem manageable. As our systems grew, however, this auto-remediation system stopped working as well. Often, when we would drain an imbalanced link the problem would just move to another one. It was clear that we needed to understand the root cause.
The Clue
The link imbalance occurred on multiple vendors’ switch and router hardware. It had multiple triggers: Sometimes the trigger was transient network congestion, such as a large bulk transfer; sometimes it was hardware failure; and sometimes it was a load spike in database queries. It wasn’t confined to a particular data center. We suspected that it was a metastable state because it would outlast the trigger, but because there were lots of patterns, it was difficult to separate cause and effect.
We did find one robust clue: The imbalanced links always carried traffic between MySQL databases and the cache servers for TAO, our graph store for the social graph.
It seemed likely that TAO’s behavior was causing the imbalance, but we had no plausible mechanism. The hash algorithm, source IP, destination IP, and destination port didn’t change during the onset of the problem; the source IP port was the only variable factor. This implies that the switch wasn’t at fault because the route is predestined before the switch gets the SYN packet. On the other hand, the TAO server couldn’t be at fault, because its pick is pseudo-random and blind. Even if the server were aware that the links were aggregated – and it isn’t – the server doesn’t know the hash algorithm or hash seed, so it can’t choose a particular route.
Lots of eyes looked at the code involved, and it all seemed correct. We weren’t using any non-standard switch settings or weird kernel settings. The code was ordinary and hadn’t had any significant changes since a year before the link imbalance bug first surfaced. We were stumped.
Collaboration and Collusion
Facebook’s culture of collaboration proved key. Each layer of the system seemed to be working correctly, so it would have been easy for each team to take entrenched positions and blame each other. Instead, we decided that a cross-layer problem would require a cross-layer investigation. We started an internal Facebook group with some network engineers, TAO engineers, and MySQL engineers, and began to look beyond each layer’s public abstractions.
The breakthrough came when we started thinking about the components in the system as malicious actors colluding via covert channels. The switches are the only actors with knowledge of how packets are routed, but TAO is the only actor that can choose a route. Somehow the switches and TAO must be communicating, possibly with the aid of MySQL.
If you were a malicious agent inside the switch, how would you secrete information to your counterparty inside the TAO application? Most of the covert channels out of the switch don’t make it through Linux’s TCP/IP stack, but latency does – and that was our light-bulb moment. A congested link causes a standing queue delay, which embeds information about the packet routing in the MySQL query latency. Our MySQL queries are very fast, so it is easy to look at the query execution times and tell if it went across a congested link. Even a congestion delay of 2 milliseconds is clearly visible with application-level timers.
The receiving end of the collusion must be in code that manages connections, and that has access to timing information about the queries. TAO’s SQL connection pool seemed suspect. Connections are removed from the pool for the duration of a single query, so careful bookkeeping by a malicious agent inside the pool could record timings. Since the timing information gives you a good guess as to whether a particular connection is routed over a congested link, you could use this information to selectively close all of the other connections. Even though new connections are randomly distributed, after a while only the congested links would be left. But who would code such a malicious agent?
Unintended Consequences in a Custom MySQL Connection Pool
Surprisingly, the code for the receiving agent was present in the first version of TAO. We implemented an auto-sizing connection pool by combining a most recently used (MRU) reuse policy with an idle timeout of 10 seconds. This means that at any moment, we have as many connections open as the peak number of concurrent queries over the previous 10 seconds. Assuming that query arrivals aren’t correlated, this minimizes the number of unused connections while keeping the pool hit rate high. As you’ve probably guessed from the word “assuming,” query arrivals are not uncorrelated.
Facebook collocates many of a user’s nodes and edges in the social graph. That means that when somebody logs in after a while and their data isn’t in the cache, we might suddenly perform 50 or 100 database queries to a single database to load their data. This starts a race among those queries. The queries that go over a congested link will lose the race reliably, even if only by a few milliseconds. That loss makes them the most recently used when they are put back in the pool. The effect is that during a query burst we stack the deck against ourselves, putting all of the congested connections at the top of the deck.
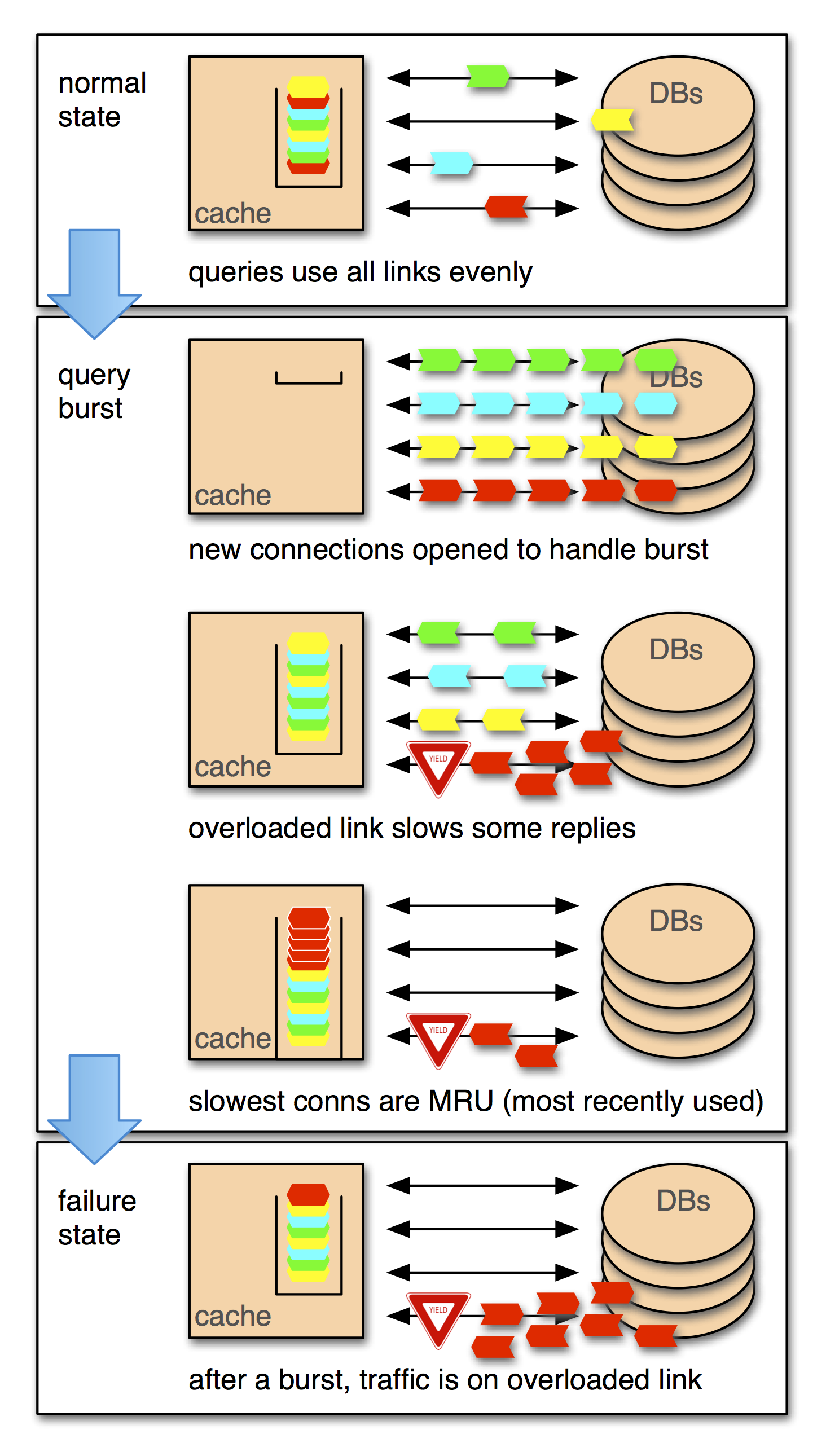
No individual cache server can overload a link, but the deck-stacking story plays out simultaneously on hundreds of machines. The net effect is that the TAO system continually probes all of the links between it and the databases, and if it finds a slow link it will rapidly shift a large amount of traffic toward it.
This mechanism explains the multitude of causes and the robustness of the effect. The link imbalance bug doesn’t create congestion but makes it metastable. After some other problem causes a link to saturate, the connection pool shifts traffic in a way that keeps the link saturated even when the original trigger is removed. The effect is so strong that the time lag between changing a switch’s hash and draining its outbound queue can allow the problem to reoccur with a new set of connections.
Simple Fix
The fix is very simple: We switched to a least recently used (LRU) connection pool with a maximum connection age. This uses slightly more connections to the database, but the databases can easily handle the increase.
We wanted to be completely sure we had resolved the problem, so we took the extra step of manually triggering it a few times. When we fixed the connection pool, we included a command that would let us switch between the old and new behavior at runtime. We set the policy to MRU, and we manually caused a congested link. Each time, we watched the imbalance disappear within seconds of enabling the LRU policy. Then, we tried unsuccessfully to trigger the bug with LRU selected. Case closed.
But how would this impact Facebook’s new fabric network? Facebook’s newest data center in Altoona, Iowa, uses an innovative network fabric that reduces our reliance on large switches and aggregated links, but we still need to be careful about balance. The fabric computes a hash to select among the many paths that a packet might take, just like the hash that selects among a bundle of aggregated links. The path selection is stable, so the link imbalance bug would have become a path imbalance bug if we hadn’t fixed it.
Lessons Learned
The most literal conclusion to draw from this story is that MRU connection pools shouldn’t be used for connections that traverse aggregated links. At a meta-level, the next time you are debugging emergent behavior, you might try thinking of the components as agents colluding via covert channels. At an organizational level, this investigation is a great example of why we say that nothing at Facebook is somebody else’s problem.
Thanks to all of the engineers who helped us manage and then fix this bug, including James Paussa, Ernesto Ovcharenko, Mark Drayton, Peter Hoose, Ankur Agrawal, Alexey Andreyev, Billy Choe, Brendan Cleary, JJ Crawford, Rodrigo Curado, Tim Eberhard, Kevin Federation, Hans Fugal, Mayuresh Gaitonde, CJ Infantino, Mark Marchukov, Chinmay Mehta, Murat Mugan, Austin Myzk, Gaya Nagarajan, Dmitri Petrov, Marco Rizzi, Rafael Rodriguez, Steve Shaw, Adam Simpkins, David Swafford, Wendy Tobagus, Thomas Tobin, TJ Trask, Diego Veca, Kaushik Veeraraghavan, Callahan Warlick, Jason Wilbanks, Jimmy Williams, and Keith Wright.




")





