
Last year, we introduced MyRocks, our new MySQL database engine, with the goal of improving space and write efficiency beyond what was possible with compressed InnoDB. Our objective was to migrate one of our main databases (UDB) from compressed InnoDB to MyRocks and reduce the amount of storage and number of servers used by half.
We carefully planned and implemented the migration from InnoDB to MyRocks for our UDB tier, which manages data about Facebook’s social graph. We completed the migration last month, and successfully cut our storage usage in half. This post describes how we prepared for and executed the migration, and what lessons we learned along the way.
UDB was space-bound
Several years ago, we changed the UDB hardware from Flashcache to pure Flash, which addressed some performance issues. MySQL with InnoDB was fast and reliable, but we wanted to be more efficient by using less hardware to support the same workload and data. With pure Flash, UDB was space-bound. Even though we used InnoDB compression and there was excess CPU and random I/O capacity, it was unlikely that we could enhance InnoDB to use less space.
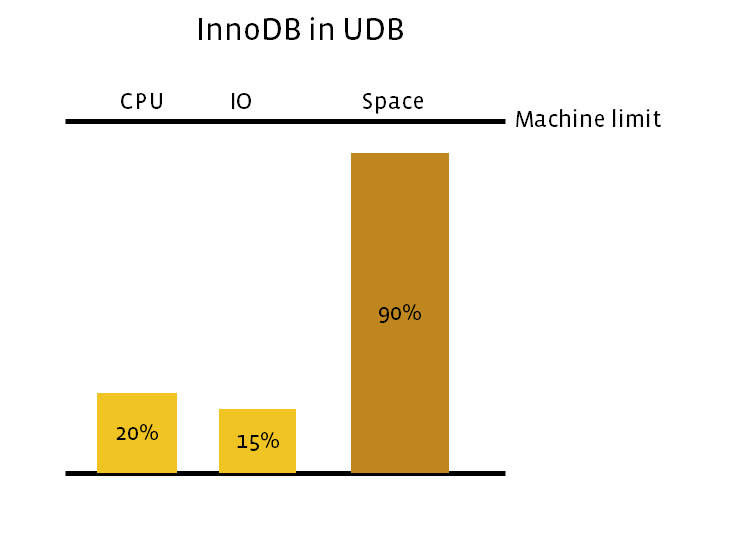
This was one of the motivations for creating MyRocks – a RocksDB storage engine for MySQL. We implemented several features to match InnoDB where the database size was much bigger than RAM, including:
- Clustered index
- Transaction (Atomicity, Row locks, MVCC, Repeatable Read/Read Committed, 2PC across binlog and RocksDB)
- Crash-safe secondary/primary
- SingleDelete (Efficient deletions for secondary indexes)
- Fast data loading, fast index creation, and fast drop table
Our early experiments showed that space usage with MyRocks was cut in half compared with compressed InnoDB, without significantly increasing CPU and I/O utilization. So we decided to fully migrate UDB from InnoDB to MyRocks.
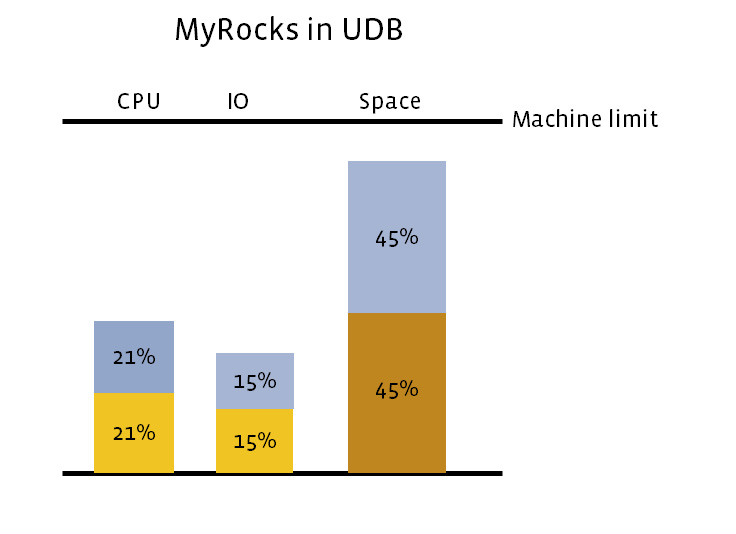
Easier migration from InnoDB to MyRocks
Database migration can be challenging for user-facing database services. In general, production OLTP database migration has to be done without stopping services, without degrading latency/throughput, without returning wrong data, and without affecting operations.
MyRocks has a unique advantage compared with other database technologies – it’s also in MySQL, so the similarities make it much easier to migrate from InnoDB. For example:
- No application change was needed because MySQL client protocols and schema definitions were the same. (There were actually some minor differences, like Gap Lock, but they were relatively easy to address.)
- Our existing MySQL administration tools could support both InnoDB and MyRocks.
- MyRocks could replicate from InnoDB. We could add a MyRocks instance by running as one of the read-only secondaries.
- InnoDB could also replicate from MyRocks. We could deploy MyRocks on primary without destroying InnoDB. This allowed us to demote MyRocks and promote InnoDB again if an issue arose in production.
- Binary logs with Global Transaction Identifier (GTID) made it possible to verify data consistency between InnoDB and MyRocks instances, without stopping replication for a long time (less than 1 second).
Data consistency verification
MyRocks/RocksDB was a newer database, so we helped prevent introducing new bugs into our database with a comprehensive data consistency verification. The verification has run continuously — both during migration and after running in production.
Primary key and secondary key consistency check. This compared row counts and column checksum between the primary and secondary keys of the same MyRocks tables. For example, if there was a column (id, value1, value2) for table t1 and there was a secondary index for (value1), the tool scanned value1 by primary key and secondary key, then compared row counts and checksum. If either the primary key or secondary key was corrupted, checksum wouldn’t match.
Consistency check across two instances. This compared primary key row counts and checksum across two different instances (MyRocks and InnoDB) within the same replicaset (primary-secondary pairs). With GTID, it is possible to start transactions with consistent snapshot with the same GTID, for both instances. Then select statements that follow (returning row counts and checksum) should be consistent between instances.
Shadow query correctness check across two instances. MySQL has a feature called Audit Plugin to capture executed queries. We created a tool to shadow (replay) captured queries to multiple instances and compare results. This made sure that production queries were seeing exactly the same results between InnoDB and MyRocks.
Migration steps
We used the following process to migrate from InnoDB to MyRocks. The fact that InnoDB and MyRocks could replicate each other made the migration a lot easier.
Deployed the first MyRocks secondary. We had one primary and four secondaries for each replicaset, across worldwide regions. For each replicaset, we created a first MyRocks instance by dumping from InnoDB (mysqldump) in the same region, then loading into MyRocks (mysql with bulk data loading and fast index creation). We stopped replication in the source InnoDB secondary instances during dump and load to make migration fast and easier. During dump and load, all read requests went to other available secondary InnoDB instances. Since MyRocks was optimized for data loading and secondary index creations, dump and load did not take much time (it could copy hundreds of GBs of InnoDB data per hour). After catching up replication and verifying consistency, we deleted the InnoDB in the same region.
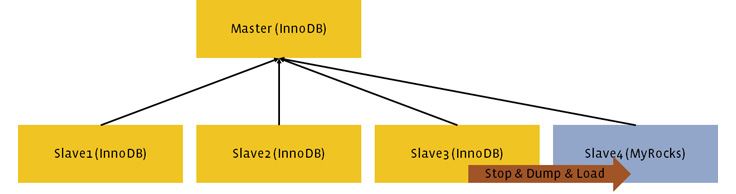
Deployed the second MyRocks secondary. We wanted to avoid operating with a single MyRocks instance, since losing the MyRocks instance would require us to dump and load again. By operating with two MyRocks instances, recovering from single instance failure could be done by online binary MyRocks copy (myrocks_hotbackup), which was much more lightweight than dump and load. Prior to MyRocks deployment, we had five InnoDB instances per replica set. We added two MyRocks instances so far followed by deleting two InnoDB instances in the same region. This resulted in three InnoDB and two MyRocks instances for each replicaset. Since MyRocks was faster for data loading, loading into MyRocks was much easier than copying to InnoDB. This allowed us to migrate without increasing the number of physical servers in use, even during migration.
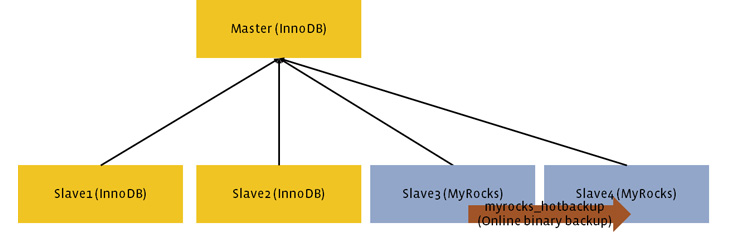
Promoted MyRocks secondary as a primary. Deploying primary was much more difficult than deploying secondary because a primary instance can serve writes as well as reads. For example, on primary, concurrent writes to the same rows happen so proper row lock handling should be implemented. Poor concurrency implementation will cause lots of errors and stalls.
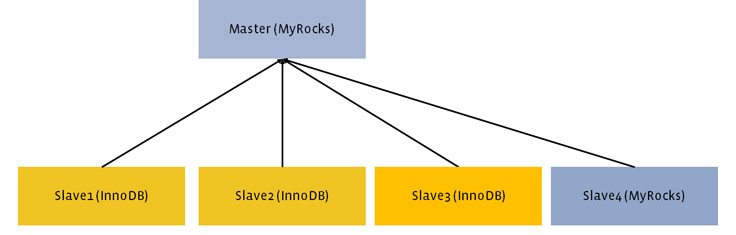
Copied MyRocks in all regions, deleted all InnoDB instances. The last step was copying MyRocks in all regions and removing InnoDB. Finally the replicaset was fully migrated from InnoDB to MyRocks.
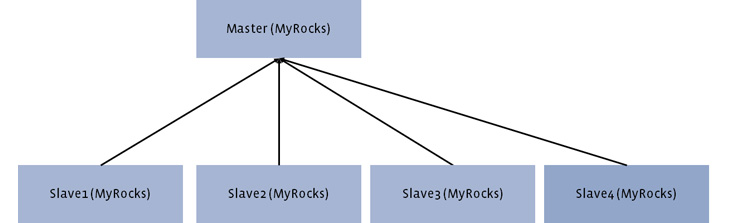
In production, we did the first two steps for all UDB replica sets. We then proceeded to the third step for many replica sets, then finally to the last step. Since primary deployment was the hardest part, we did lots of testing before moving forward. We extended our shadow query testing tool to cover primary traffic testing, so that we could fix any concurrency bugs before deploying primary in production.
Other technical tips
While we used direct I/O in InnoDB, MyRocks/RocksDB had limited support for direct I/O so we switched to use buffered I/O. Older Linux kernel had known issues that involved heavy buffered I/O usage causing swap and virtual memory allocation stalls. Our Linux kernel team at Facebook fixed the vm allocation stalls in Linux 4.6, and we upgraded the kernel to v4.6 prior to the migration.
We also run multiple MySQL instances per machine. Each instance size was much smaller than the 5TB flash storage capacity, which helped improve database operations like backups, restore, creating replicas, and preventing replication lags. During migrations, we gradually created MyRocks instances, followed by deleting InnoDB instances. On Flash storage, aggressive file deletions caused long TRIM stalls, which might take seconds to tens of seconds. We were aware of the restrictions and created a simple tool to delete files slowly in tiny chunks. Instead of deleting 100GB InnoDB data files with the “rm” command, the tool divided large files into multiple ~64MB chunks, then deleted each chunk with short sleeps. We slowed down the deletion speed to around 128MB per second.
Lessons learned
Efficiency is important to our operations. Having completed the migration quickly and without causing production problems made us really happy. During the course of developing MyRocks and migrating to it, we learned several important lessons.
- Estimated migration time should be one of the main criteria in choosing hardware technology. For example, taking five years to complete a migration instead of one year can lower the impact on storage savings because you would have to continue to purchase new hardware before the migration was done. Automating and simplifying tests also helped make the migration easier, including:
- Sending shadow production read/write traffic and monitoring regressions (especially the number of errors, stalls and latency)
- Checking InnoDB and MyRocks data consistency
- Intentionally crashing MyRocks secondary and primary instances and verifying that they could recover
- Understand how the target service is used. It was important for us to decide what features to add in MyRocks with higher priority. We added several important features to migrate easier, such as detecting queries using Gap Locks, Bulk Loading, Read Committed isolation levels. Prioritizing features properly will help to migrate easier and quickly. But to do that, you need to know better about how services work.
- Start small. Ideally, new software should first be deployed on a very small, read-only instance, where it can be rolled back as needed. Switching an entire service via config file and hoping it will work is not what Production Engineers (Site Reliability Engineers) should do.
- MyRocks is an open source software, which allows us to work with others to create features and find and fix bugs.
Future plans
Replacing InnoDB with MyRocks in our main database helped us reduce our storage usage by half. We are continuing to make MyRocks and RocksDB more efficient, including consolidating instances more aggressively to free up machines for other purposes. We are also working on cross-engine support. MyRocks is optimized for space savings and reducing write amplification, while InnoDB is more optimized for reads and has more niche features such as gap locking, foreign keys, fulltext indexes, and spatial indexes. Our current MyRocks development does not implement many niche features but plans to support multiple engines reliably. Running both InnoDB and MyRocks in the same instance will allow people to use InnoDB for small, read-intensive tables, and MyRocks for everything else, which is a common feature request from our external community. Finally, we will work to support MyRocks for the upcoming MySQL 8.0.











