
Think about the last post you liked — it most likely involved a photo or video. But, until recently, online search has always been a text-driven technology, even when searching through images. Whether an image was discoverable was dependent on whether it was sufficiently tagged or had the right caption — until now.
That’s changing because we’ve pushed computer vision to the next stage with the goal of understanding images at the pixel level. This helps our systems do things like recognize what’s in an image, what type of scene it is, if it’s a well-known landmark, and so on. This, in turn, helps us better describe photos for the visually impaired and provide better search results for posts with images and videos.
Building the “AI factory”
In order to weave AI into the Facebook engineering fabric, we first needed a general-purpose platform that our engineers could leverage at scale. Called FBLearner Flow, this system was designed so engineers building machine learning pipelines didn’t need to worry about provisioning machines or deal with scaling their service for real-time traffic. We’re currently running 1.2 million AI experiments per month on FBLearner Flow, which is six times greater than what we were running a year ago.
As this platform has become more widely used, we’ve continued to build on top of it. From tools to automate the process of machine learning to dedicated content understanding engines, we’ve built an active ecosystem that allows engineers to write training pipelines that parallelize over many machines so it can be reused by any engineer at the company.
The computer vision platform
After starting out as a small research project out of Facebook AI Research, the FBLearner Flow platform and team transferred to the Applied Machine Learning team when it reached production scale and is now the engine for the current computer vision team at Facebook.
Lumos, built on top of FBLearner Flow, is the platform we built for image and video understanding. Facebook engineers do not need to be trained in deep learning or computer vision in order to train and deploy a new model using Lumos. The Lumos platform keeps improving all the time, both through all the newly labeled data we feed it, and through the annotated data from the applications our teams build.
Advances in deep learning have allowed us to make big improvements in image classification — questions like “What is in the image?” and “Where are the objects?” are being answered by systems more accurately than ever. We’ve advanced this research by designing techniques that detect and segment the objects in a given image.
When these techniques are applied at Facebook, photos pass through a deep-learning engine that can segment the image and identify objects and scenes, and attach even more meaning to the photo. This provides a rich set of data that any Facebook product or service can use. More than 200 visual models have been trained and deployed on Lumos by dozens of teams, for purposes such as objectionable-content detection, spam fighting, and automatic image captioning. The applications are wide-reaching, with everyone from our Connectivity Labs to Search to the Accessibility team using the technology.
Active language for accessibility
We are currently applying the image understanding work in a way that has been instrumental in helping improve automatic alt text (AAT) for photos, a technology that can describe the contents of photos for people who are visually impaired.
Until recently, these captions described only the objects in the photo. Today we’re announcing that we’ve added a set of 12 actions, so image descriptions will now include things like “people walking,” “people dancing,” “people riding horses,” “people playing instruments,” and more.
This update to AAT was executed in two parts, with Lumos allowing for quick, scalable iteration. A considerable percentage of photos shared on FB include people, so we focused on providing automatic descriptions involving people. The AI team gathered a sample of 130,000 public photos shared on Facebook that included people. Human annotators were asked to write a single-line description of the photo, as if they were describing the photo to a visually impaired friend. We then leveraged these annotations to build a machine-learning model that can seamlessly infer actions of people in photos, to be used downstream for AAT.
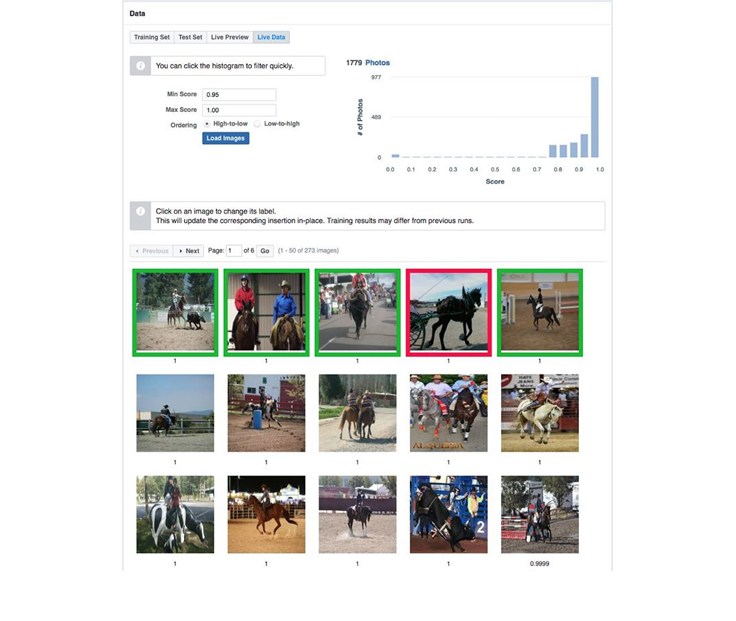
Lumos allowed for quick iteration on this task, with an interface to leverage labeled examples from a previously trained model for another task. Example: If we are training a “person riding a horse” classifier and want to add examples of images that include horses (sans people riding them), we could use a portion of labeled examples from a model that learns to classify whether a photo has a horse.
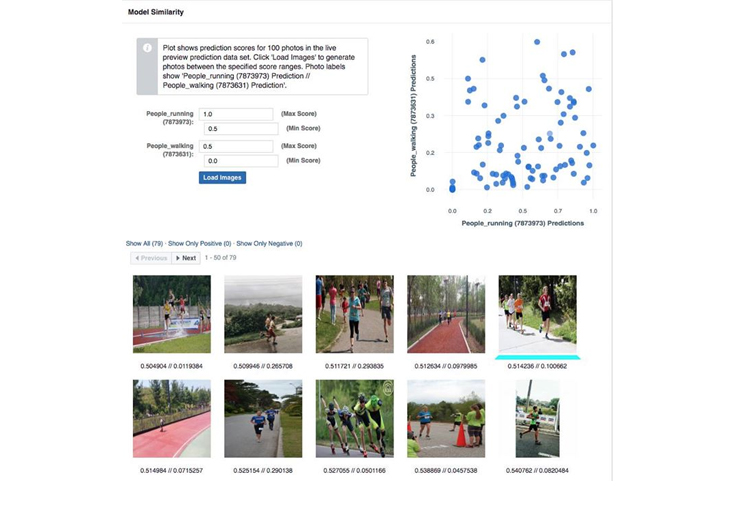
Lumos allows for generating training data through a combination of retrieval and clustering. Given a set of tags or search terms, the platform can retrieve a fraction of public images that have captions matching those tags. These images are then semantically clustered to make for faster labeling — Lumos users can choose to annotate clusters as negative or positive examples for their use case, at either the cluster level or individually for each image in the cluster. This can help facilitate seeding a classification task with an initial set, followed by iterative training to obtain a higher precision/recall classifier.
While the AAT application is important because it can bring a whole new level of access to visually impaired users of Facebook, there are other applications that simply offer convenience, like unearthing a new search parameter.
More descriptive photo search
With Lumos, we’re able to deliver visual search to our community. An example: When you’re thinking back on your favorite memories, it can be hard to remember exactly when something took place and who took the photo to capture the moment.
Today, we’re announcing that we’ve built a search system that leverages image understanding to sort through this vast amount of information and surface the most relevant photos quickly and easily. In other words, in a search for “black shirt photo,” the system can “see” whether there is a black shirt in the photo and search based on that, even if the photo wasn’t tagged with that information.
Using Facebook’s automatic image classifiers, just like the ones used in the AAT example, you can imagine a scenario where someone could search through all the photos that his or her friends have shared to look for a particular one based on the image content instead of relying on tags or surrounding text.
To make sure the search results are relevant to the query, we have to have a good understanding of the actual photo content. In this case, the team used cutting-edge deep learning techniques to process billions of photos and understand their semantic meaning. In particular, the photo search team used the following signals to better rank photos:
Object recognition: The underlying image understanding model is a deep neural network with millions of learnable parameters. It builds on top of the state-of-the-art deep residual network and is trained on object recognition using tens of millions of photos with annotations. It can automatically predict a rich set of concepts, including scenes (e.g. garden), objects (e.g. car), animals (e.g. penguin), places and attractions (e.g. the Golden Gate Bridge), and clothes items (e.g. scarf).
Image embeddings: It also generates high-level semantic features, which are quantized versions of the output of the last few layers of the deep neural net. This rich information is useful for refining image search results.
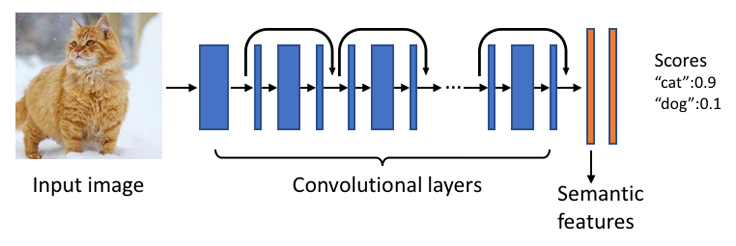
The original semantic features are high-dimensional float vectors, which use up a lot of storage for indexing — especially when we have to index so many photos. By leveraging quantization techniques, the features are further compressed into a few bits while still preserving most of the semantics. The bit representation is used as the compact embedding of the photos, and could be directly employed in ranking, retrieval, and photo de-duplication.
One way to build this is to extract the predicted concepts and categories from an image, then parse the search query to link entities and extract concepts, and then use a similarity function between the two sets of concepts to determine relevance.
This is a good start but the team did not stop at using predicted image categories — we went much further and also used joint embeddings of queries and images, to dramatically improve both precision and recall.
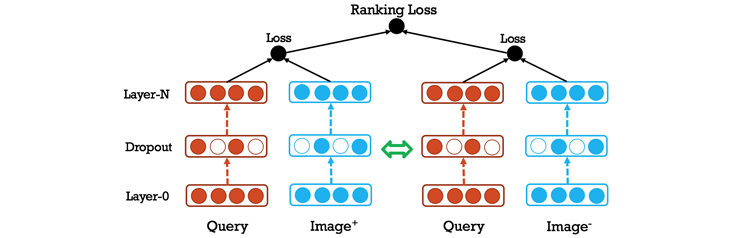
We set this up as a multimodal learning to rank problem. In addition, we also used a similarity measure between images to make sure the image search results are diverse.
What’s next
Bringing image classifiers through Lumos into production took a lot of work by a lot of teams. While these new developments are noteworthy, we have a long and exciting road ahead and are just scratching the surface of what is possible with a self-serve computer vision platform. With computer vision models getting pixel perfect and Facebook advancing into video and other immersive formats, Lumos will help unlock new possibilities in a reliable, fast, and scalable way and pave the road for richer product experiences in the near future.











