
- We introduced Open/R, a custom-built, extensible distributed network application platform.
- Open/R was originally designed as a shortest-path routing system to power Terragraph, our multi-node wireless network that delivers high-speed internet connectivity in dense urban areas via short-hop transmission between small nodes.
- Open/R's modular and extensible design allows for additional applications on top of the basic routing function, and we have successfully adapted the platform for use with other parts of our networking infrastructure.
- Open/R makes it possible to prototype and deploy new network applications much more quickly than with the industry’s standard development process. Being able to iterate quickly is central to our ability to improve the speed, efficiency, and quality of internet connectivity around the world.
- We will continue to iterate on Open/R and determine the best approach for contributing the software to the open source community and to the Telecom Infra Project (TIP).
We recently announced Terragraph, a multi-node wireless network that delivers high-speed internet connectivity to dense urban areas using small nodes. Terragraph is functionally more similar to wired networks in terms of bandwidth and latency, and it features complex topology and intelligent Layer 2 technology, allowing traffic to be sent only where it is needed.
Today at Networking @Scale, we introduced Open/R, the extensible distributed network application platform that powers the Terragraph network. Although Open/R began as routing software for Terragraph, it has evolved into a platform that allows us to rapidly prototype and deploy new applications in the network. We have also successfully adapted Open/R for use with other parts of Facebook's networking infrastructure.
With Terragraph and Open/R, we can produce cost-effective solutions and iterate more quickly, which in turn will help us improve the speed, efficiency, and quality of internet connectivity around the world. We are continuing to iterate on these technologies with the ultimate goal of contributing them to the open source community and to the Telecom Infra Project (TIP) for use in the broader ecosystem.
Powering Terragraph
We first got the idea of building our own routing system when we were trying to solve fast-recovery challenges for the Terragraph network. Looking at existing open source projects, we found they were hard to extend quickly and in a supportable fashion. Virtually all of them were written in C for performance reasons and lacked higher-level abstractions and good testing frameworks. Given this, we decided to build our own system. We kept it simple by reusing as much open source code as possible.
Moving fast
The Open/R software enables rapid prototyping and deployment of new applications to the network much more frequently than the industry’s standard development process. To create an interoperable standard, the industry's process is often lengthy due to code being built independently by multiple vendors and then slowly deployed to their customer networks. Furthermore, every vendor has to accommodate for the demands of numerous customers — complicating the development process and requiring features that are not always useful universally.
With Open/R, Facebook's network is in our full control, and as such, we don't need to ensure interoperability with every implementation or need to support every known legacy feature; we can focus on the features we need most and add more functionality as needed. This allows us to apply the same fast and iterative development process that is the standard within Facebook to our network development.
It may sound like this rapid prototyping and deployment of new applications sacrifices reliability for speed, but that's not the case. We view reliability as a system property that comes from combining network design, operational practices, and the ability to quickly write and continuously deploy new code. We build our networks segmented into multiple partitions, such that a failure in one partition does not affect the others. Furthermore, we work on rapid failure detection and mitigation, and we view the ability to roll new updates quickly as a factor that enables us to fix things more efficiently.
Design
At its core, Open/R generalizes the concept of a replicated state database found in well-known link-state routing protocols such as OSPF and ISIS. It uses this as an underlying message system upon which we can build multiple applications. Distributed routing is just one of the applications that leverages this message bus. We didn't want to get bogged down in discussions over the lower-level protocol details, such as frame formatting and handshakes, so we decided to simply leverage Thrift for all message encoding and use the well-documented and mature open source ZeroMQ library for all message exchange, whether it's intra-process or inter-process.
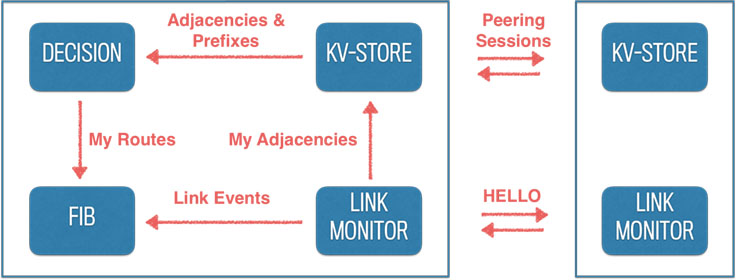
ZeroMQ typically uses TCP to establish transport connections and allows for flexible message patterns (with PUB/SUB being one important example) that we actively leverage. While it might sound heavyweight compared with OSPF and ISIS, which use their own “lightweight” transports, we haven't found this to be an issue in modern networking hardware, such as the devices we use for Terragraph or the Wedge and 6-pack boxes running FBOSS in our data center networks. On the plus side, using ZeroMQ saves a lot of work implementing and testing the low-level aspects of the system, and it allows us to use the same framework for intra-application and inter-application messaging.
The module called KV-STORE in the diagram uses ZeroMQ sessions to form a distribution mesh that could be either in band with the network, mimicking the topology, or out of band. KV-STORE provides a simple ZMQ-based API to publish key-value pairs and subscribe to changes in the state database. Even though key-values are opaque strings of arbitrary size, we always use Thrift to encode values, which allows us to get a serialization/deserialization code for multiple languages for free. If needed, a CurveCP-based security model for ZeroMQ could be enabled for each connection to fully encrypt and authenticate all message exchange on the wire.
The LINK MONITOR module interacts with the link-layer aspects of the node it runs on. It detects new links coming up or down via the Netlink protocol and starts a simple “hello” protocol on the newly discovered links. This protocol uses UDP messages sent to a link-local IPv6 multicast address. It serves the purpose of detecting alive neighbors and validating bidirectional relationships. It works the same for point-to-point and multipoint interfaces. In addition, it carries the public key of the neighbor node to establish secure message exchange channel with ZeroMQ. Upon new link discovery, LINK-MONITOR publishes its active set of neighbors to KV-STORE, using its local hostname as part of the publication key. This information is then disseminated through the global messaging infrastructure.
The DECISION module acts as a client to KV-STORE and feeds upon the link and prefix information published by every other node in the network. Similar to OSPF and ISIS, it uses the Dijkstra SPF algorithm to compute the shortest paths in the network. However, in addition to basic SPF, we also compute loop-free-alternatives (LFAs) for every node in the network, effectively implementing loop-free multipath logic. The output of the DECISION module is a full routing table published to the FIB module, which provides paths in either primary/backup fashion or loop-free weighted multipath.
The FIB (forwarding information base) module is the one that interacts with the routing hardware on the network platform. It consists of two parts: The first is the hardware-independent FibAdapter, which interacts with the DECISION module and consumes the published routing tables. It computes the routing deltas to add/delete in the forwarding database and communicates them to the second part, FibAgent, which is a Thrift service exposing simple API to receive routing updates. An important part of this API is the ability to update the forwarding tables of the device with a batch of new routes. A good example of a FibAgent is the FBOSS agent process running on a device (this was used as the model for other implementations).
The last piece of the system is the ability of LINK-MONITOR to inform the FIB module of link events. This allows the FIB to quickly update the forwarding database and remove the missing next-hops, all without waiting for the DECISION module to recompute the new routing table. This allows for fast failure recovery while at the same time keeping the computational overhead low, i.e., not needing to run SPF immediately in response to local events. We deployed a similar technique in FBOSS for 6-pack, the modular switch platform used in Facebook's fabric. Naturally, this is possible only if a given destination is provided with multiple alternative paths that the DECISION module has precomputed.
Scalability and testing
Stability and scalability in the presence of constant network churn are concerns for any distributed system. It has been traditionally believed that link-state protocols do not scale well with network size, mainly because they need to disseminate large volumes of information while building upon hardware platforms and channels with limited resources. This made those protocols susceptible to network meltdown. One of our goals with Open/R was to test the scaling limits of the distributed state protocols with modern hardware. So far we have been able to scale to networks with multiple thousands of nodes, while maintaining stable system behavior.
To get there, we heavily optimized the message flooding logic used by KV-STORE in order to be more efficient when distributing state in large networks. We implemented the usual self-stabilizing features commonly present in link-state protocols, such as exponential backoff and event dampening, to reduce the impact of rapid network state changes. To validate this thoroughly, we built an extensive emulation test-bed that allows us to implement very large and complex network topologies and to stress-test the resulting setup. In addition to the suite of unit and integration tests, this emulation framework is used heavily to validate every new feature in Open/R and to detect regressions.
Conclusion
Though it was initially designed specifically for the Terragraph project, Open/R has been successfully adapted for use with other parts of our networking infrastructure, and we plan to open-source it at some point. The components of Open/R described in previous sections constitute the minimal routing solution for any network. It was straightforward to add more applications on top of routing, such as link utilization measurement, shaping weight computation for bandwidth fairness, and MPLS label allocation for segment routing purposes.
Contrary to other approaches that focus on removing intelligence from the network and placing it in a central controller, we believe that autonomous network functions play an important role. Those in-network, autonomous functions are combined with centralized controller logic, such as computing optimum traffic engineered paths, which is how we leverage Open/R in some backbone network applications, replacing the traditional IGP and adding new functionality on top of the basic routing function. Using both centralized and distributed control throughout different domains in our network, often in a hybrid fashion, ultimately helps make the network more reliable and easier to manage.
Many people contributed to this project, but the core team members — all of whom were instrumental in making this project happen — are Anant Deepak, Tian Fang, Saif Hasan, Xiaohui Liu, Paul Saab, Manikandan Somasundaram, and Jimmy Williams.



")






